


Audio and acoustics

Microsoft Research Blog
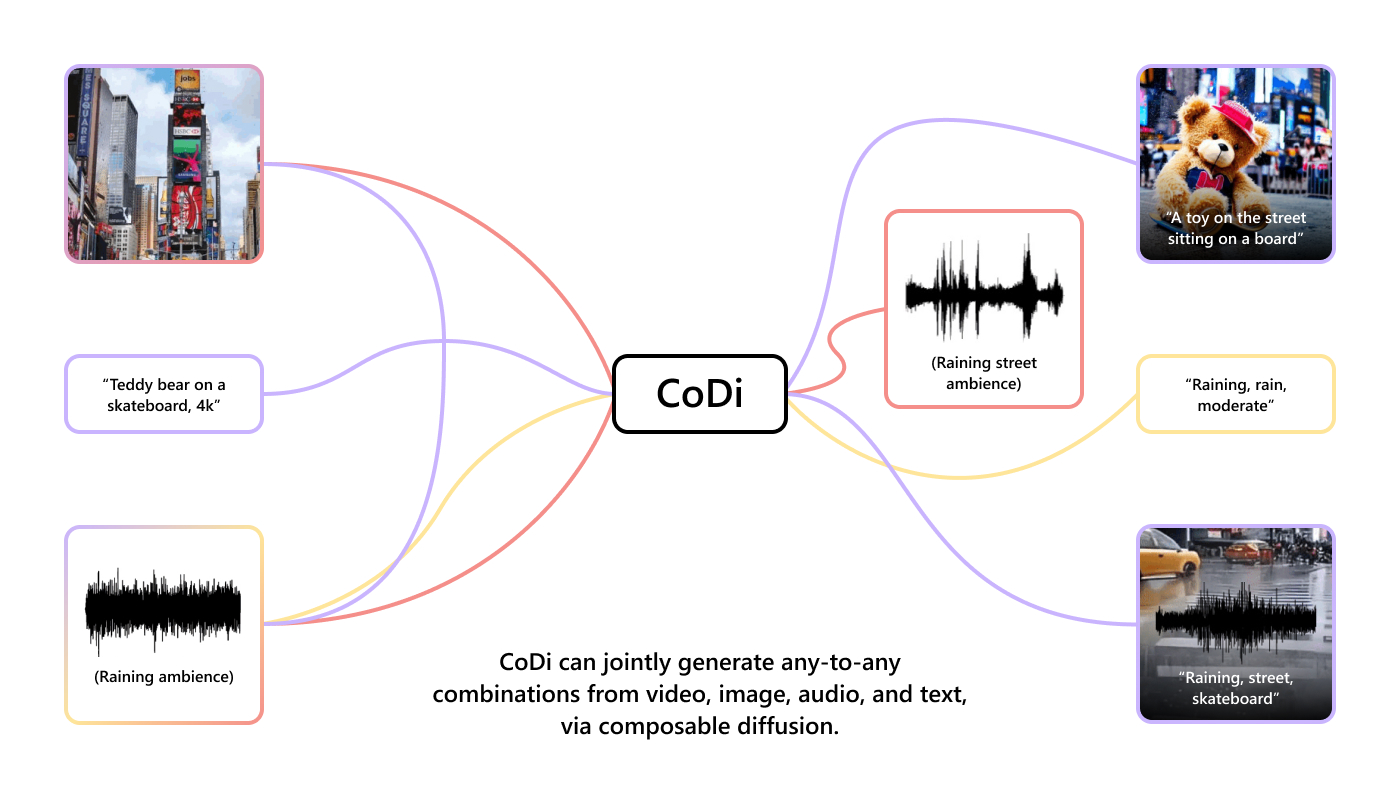
Breaking cross-modal boundaries in multimodal AI: Introducing CoDi, composable diffusion for any-to-any generation
Imagine an AI model that can seamlessly generate high-quality content across text, images, video, and audio, all at once. Such a model would more accurately capture the multimodal nature of the world and human comprehension,…
Project
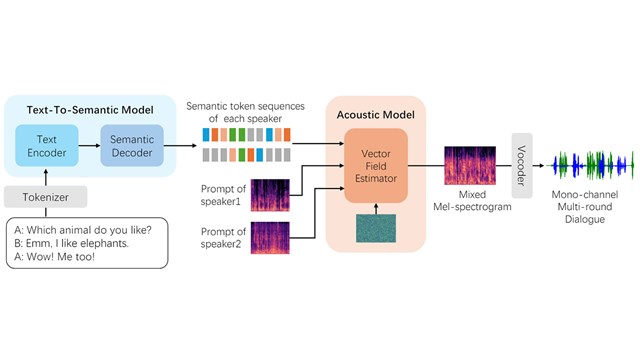
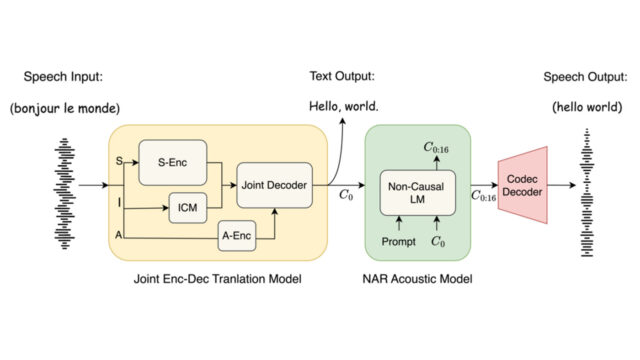
VALL-E
Neural codec language models for speech synthesis We introduce a language modeling approach for text-to-speech synthesis (TTS). Specifically, we train a neural codec language model (called VALL-E) using discrete codes derived from an off-the-shelf neural…
Publication