

By Yadong Lu1, Lingrui Xu2, Chao Huang2, Ahmed Awadallah1
1Microsoft Research, 2The University of Hong Kong
Instead of solving web tasks by predicting where to click one at a time, we only give the model a terminal where it has the full freedom to spawn browser sessions, and to explore websites through writing code. The final result was a reusable program to complete any web tasks. We found this minimal harness to be surprisingly effective in solving web tasks.
TL;DR
- Existing web agents often drive a persistent browser session one action at a time. We instead reduce the web-agent harness to a deliberately minimal terminal-based setup: three modules, roughly 1K lines of code, one agent loop, and no multi-agent orchestration. The agent emits bash commands and controls the browser by writing Playwright code, reaching SOTA results on Odysseys and Online-Mind2Web with a 100-step budget.
- Because actions are expressed as code, the agent can naturally chain many web interactions within a single step, and spawn multiple browser sessions, making execution far more efficient than predicting one primitive action at a time.
- We show the resulting script can be packaged as a reusable CLI with arguments. In a cost analysis, GPT-5.4 averages $2.37 per task, yielding a reusable RPA-style script. With our crafted tools, even a smaller model (Qwen3.5-9B) achieves strong performance on the hard split of Online-Mind2Web.
- Once a task script is crafted, it can be shared and reused across platforms—e.g., Codex, Claude Code, and OpenClaw.
Beyond step-by-step web interaction in a stateful browser
The dominant paradigm for web agents today treats the browser session itself as the agent’s workspace. At each step, the model receives the current page state—through a screenshot, or page state text—and predicts the next operation to apply to that same session. This operation may be a low-level action such as click, type, or scroll; a structured command such as selecting a DOM element; or, more recently, a short code snippet executed through a CLI tool call. In all cases, they share a common constraint: the agent is required to predict web actions one step at a time within a predefined interaction loop.
This design was useful when LLM agents had limited ability to reason, code, and recover from errors. A carefully engineered harness helped bridge the gap between what the model could reliably produce and what real web tasks required. But as models become stronger—especially at writing and debugging code—the same harness becomes a bottleneck, constraining the agent to a narrow interaction loop instead of letting it solve the task more flexibly.
Webwright builds upon this view. We separate the agent from the browser, and treat the browser as something the agent can launch, inspect, and discard while developing a program. The persistent artifact is not the browser session, but the code and logs in the local workspace. The agent can write exploratory scripts, spawn fresh browser sessions, and freely decide when to capture screenshots, inspect failures, and iteratively refine its code—much like a human engineer developing a robotic process automation (RPA) script. This approach has two obvious advantages:
First, Webwright enables robust and reusable interaction with web environments. Instead of relying on fragile pixel-level actions, a coding agent with a terminal and a local workspace can interact with the underlying structure of a webpage—querying elements, waiting for conditions, and handling dynamic behaviors such as lazy loading or re-rendering. This makes the agent far less sensitive to UI variations across sites and platforms. Moreover, the resulting scripts are reusable: once a workflow is encoded as a program, it can be rerun, adapted, and shared across tasks, rather than rediscovered from scratch each time.
Second, Webwright allows for efficient composition of complex workflows. Rather than issuing one primitive action at a time, a coding agent can naturally express multi-step interactions—such as selecting a date or filling out an entire form—as a compact program. Loops, functions, and abstractions allow the agent to generalize across similar tasks (e.g., selecting different dates) without repeatedly predicting similar sequences of low-level steps. This significantly reduces the number of interaction rounds, improves execution speed, and mitigates the accumulation of errors from long action chains.
Despite the simplicity of this setup, we find that it is surprisingly effective in solving complex and especially long horizon web tasks.
Completing web tasks in a terminal
Webwright implements this idea with a deliberately minimal harness. The system has three core components: a Runner, a Model Endpoint, and a terminal Environment. Each component is implemented as a single module: the runner is about 150 lines of code, the model interface about 550 lines, and the environment about 300 lines. There is no multi-agent orchestration or complex planning hierarchy—just a single agent loop. Given a user task, the Runner sends the current context to the model. The model returns an action, which is parsed into a thinking block and a shell command block. The command is then executed in the Environment, which manages a local workspace and returns observations such as terminal output, logs, screenshots, or error tracebacks. These observations are added back into the context, and the loop continues until the agent completes the task.
This minimal design is intentional. All intermediate code, logs, screenshots, and results are stored in the workspace, making each run easy to inspect. By keeping the harness small and avoiding unnecessary orchestration, Webwright is easier to debug, adapt, and build on top of.
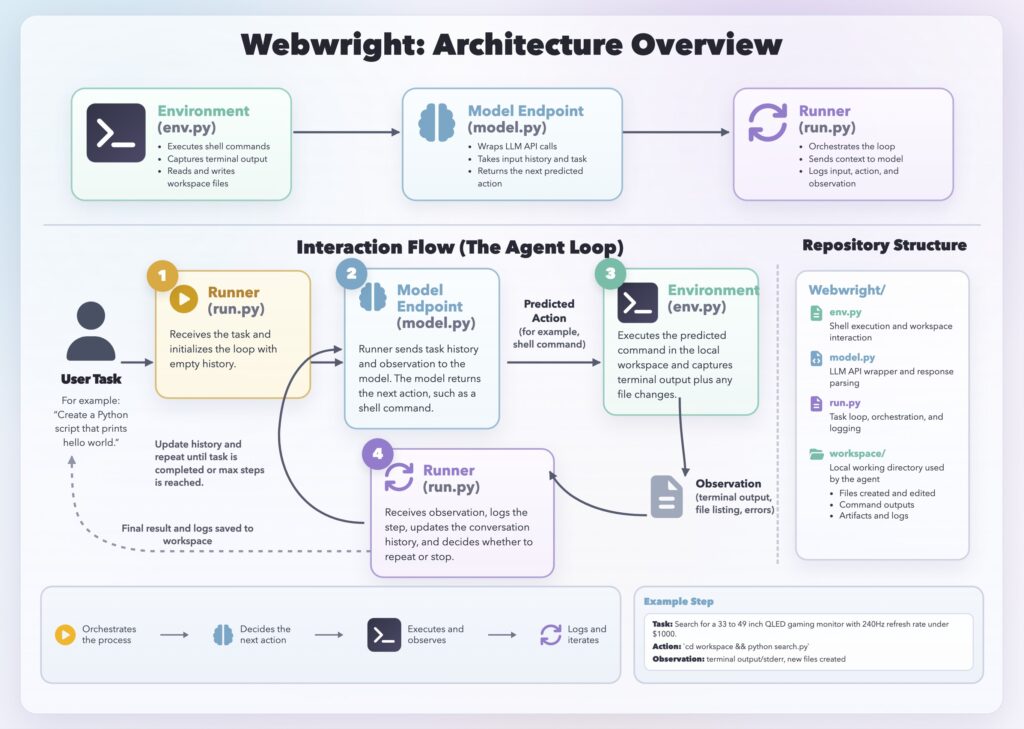
Figure 1: Webwright architecture overview and the agent interaction loop.
What are the challenges we overcome?
Premature “done” and context explosion are the two core issues. With open-ended bash actions, the model must self-report completion and often claims success without actually finishing, so we added a simple gate: the agent needs to generate a self-reflection config, run a final script in a fresh folder with logs and screenshots, and pass its own self-reflection judgement that outputs success/failure before emitting done: true; otherwise, the flag is dropped and it retries. Meanwhile, we empirically found long coding trajectories quickly exceed context limits, so we compact history every 20 steps into a single summary.
How does the agent perform?
Online-Mind2Web
Online-Mind2Web is a popular benchmark for assessing how well web agents perform on real, live websites. It includes 300 tasks spanning 136 widely used sites across diverse domains, and uses an automated evaluation framework powered by an LLM-as-a-Judge system.
We evaluated the performance of the GPT-5.4 and Claude Opus 4.7 using our harness on the full 300-task Online-Mind2Web benchmark. To make it compatible with the original eval settings, we enforce the agent to save critical point screenshots and to log actions during the run through prompting. We report the auto eval numbers with the default eval settings and found both models’ performance very competitive. And the GPT-5.4 performance 86.67% represents the highest among all the open sourced harness recipes of the AutoEval category of Online-Mind2Web benchmark.
The results highlight a strong overall performance from GPT-5.4 on Online-Mind2Web, especially on easy and medium tasks, where it consistently outperforms Claude Opus 4.7 and benefits further from increased number of steps (reaching 96.2% on easy and 88.1% on medium at N=100). This advantage carries through to the overall metric, with GPT-5.4 achieving the higher aggregated accuracy at 86.7% compared to Claude’s 84.7%. However, for hard tasks Claude Opus 4.7 performs better than GPT-5.4 at N=50 and N=100 (80.5% vs. 76.6%), suggesting it performs more effectively in the most challenging especially long horizon scenarios. We also compare against our reproduced GPT-5.4 baseline in a conventional screenshot-based agent setting, where the model predicts x,y coordinates for clicks and typing actions. Using the same underlying model, Webwright achieves substantial gains across all three difficulty categories, highlighting the benefit of code-driven terminal based approach over step-by-step coordinate prediction.
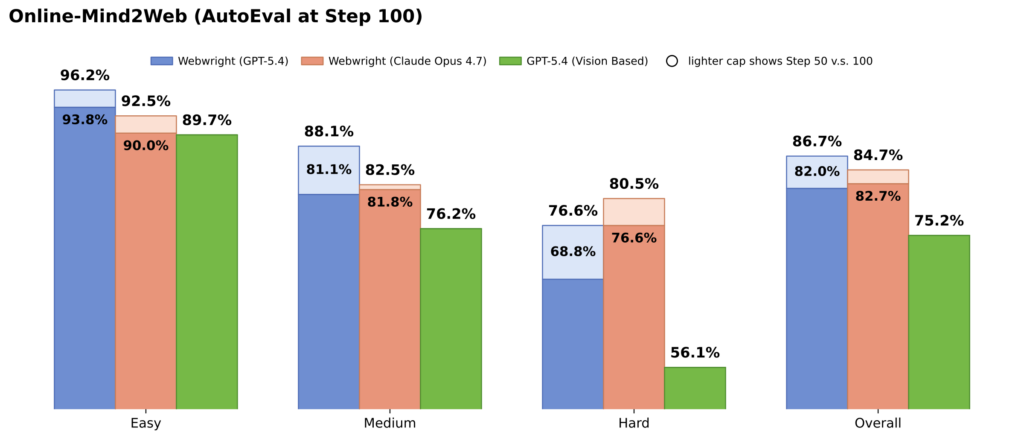
Figure 2: Online-Mind2Web accuracy by difficulty — N=50 base, stacked to N=100.
Our pipeline also supports output parameterized cli tools for each of the user tasks, which can be reused later. We also evaluated the performance of a small Qwen-3.5-9B model on tasks where the websites have more than 5 tools. We show that, when augmented with tools, a small model is able to select the correct tools and complete the tasks.
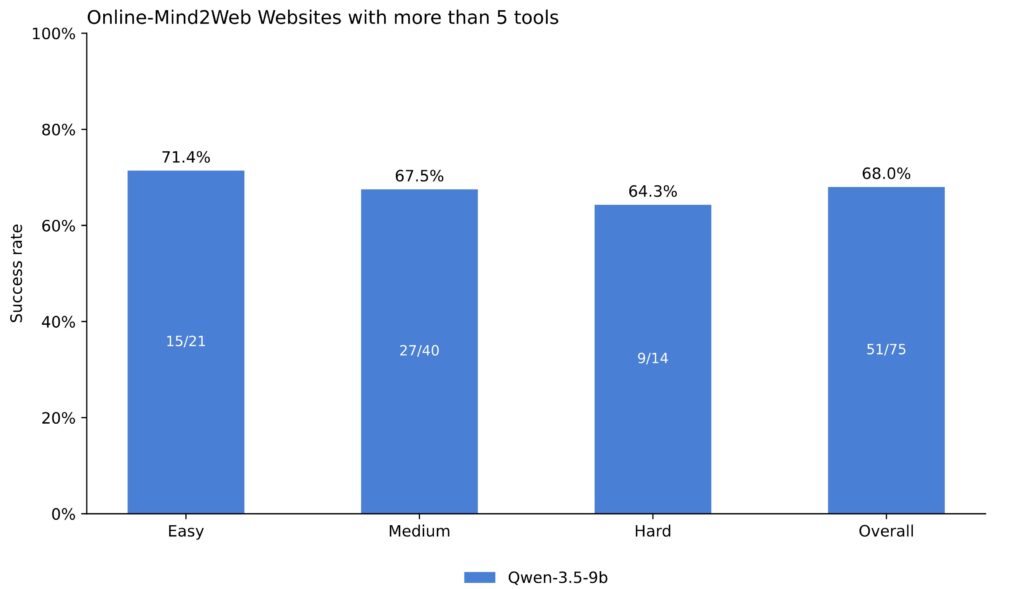
Qwen-3.5-9B success rate on Online-Mind2Web websites with more than 5 tools.
Odysseys
The Odysseys is a new web agent benchmark designed to evaluate web agents on realistic, long-horizon browsing tasks—multi-step workflows that span multiple websites and require sustained planning, memory, and cross-page reasoning. In total there are 200 tasks, and task instructions average 272.3 words (median 277.5, range 76–387), reflecting the detailed, multi-step nature of real-world web workflows.
In the current leaderboard (April 2026), the best-performing model is Opus 4.6, with a top score of 44.5 (average steps: 81.3). This corroborates with our observation in the Online-Mind2Web evaluation that Opus is stronger at the hard category of tasks compared to GPT-5.4. Webwright, powered by GPT-5.4, reaches 60.1% (average steps: 76.1), representing a 35.1% improvement over the previous state of the art. Compared to the base GPT-5.4 performance of 33.5%, this corresponds to a 79.4% relative improvement.
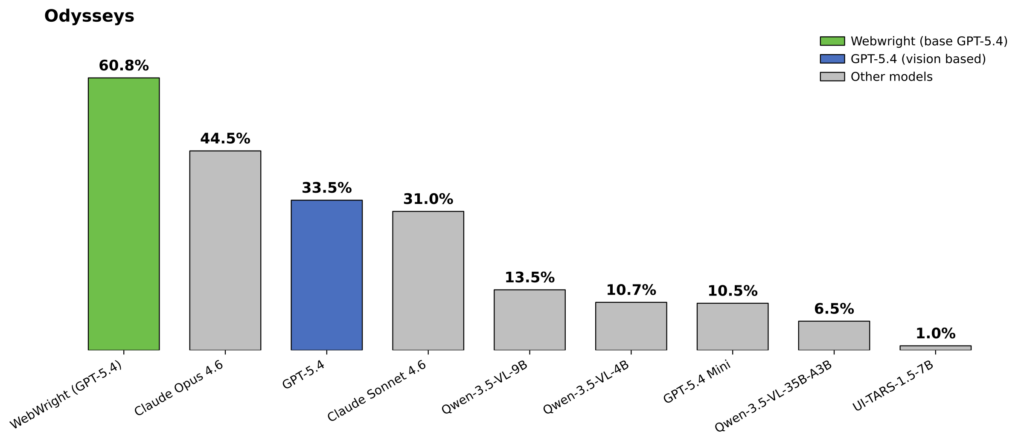
Odysseys leaderboard: Webwright with GPT-5.4 vs. base GPT-5.4 and other vision based models.
Where do the tokens go?
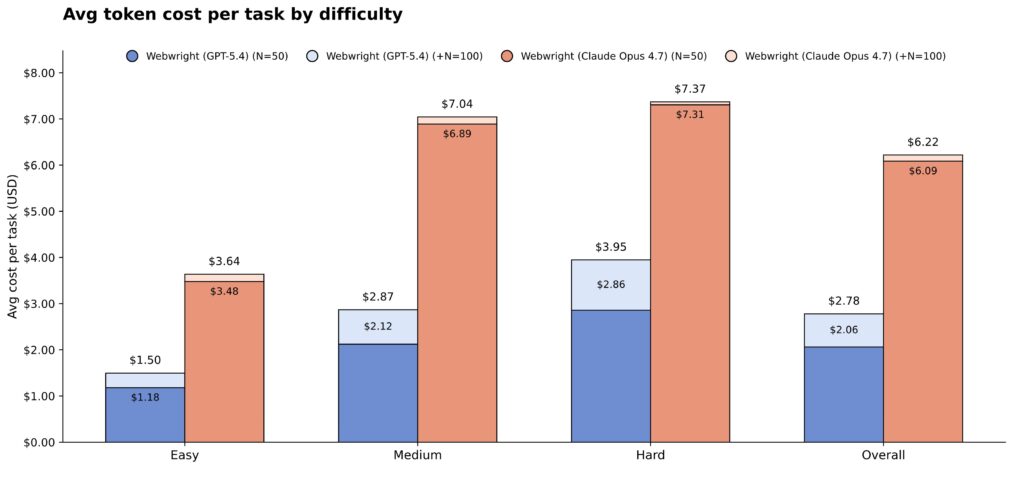
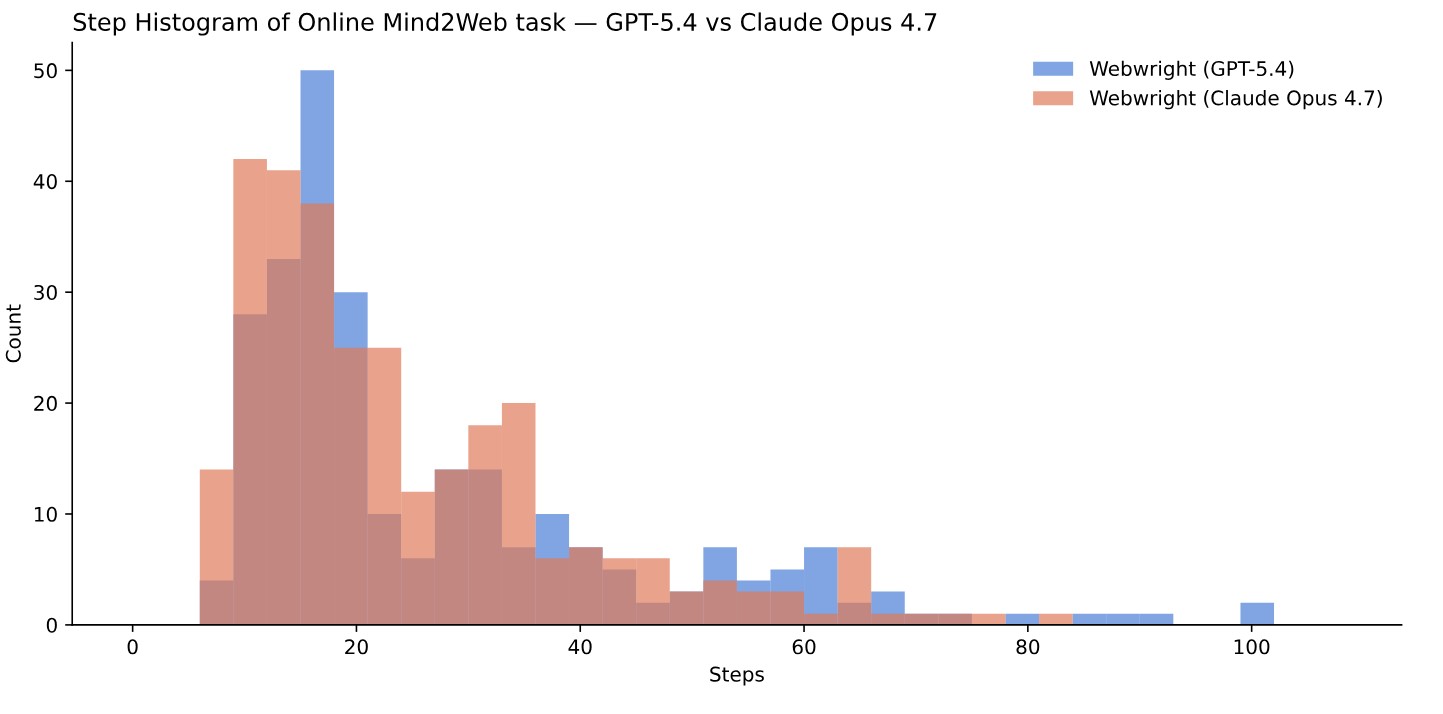
Figure 3: Distribution of number of steps across 300 Online-Mind2Web tasks for GPT-5.4 vs. Claude Opus 4.7.
We conducted an analysis for the cost of running the Online-Mind2Web benchmark. We observe most of the tasks finished within the first 50 steps for both GPT-5.4 and Claude Opus 4.7. Claude Opus 4.7 is noticeably more efficient in number of steps used to solve the task (mean: 21.9 steps) compared to GPT-5.4 (mean: 26.3 steps). However, the cost of Claude Opus 4.7 is priced significantly higher compared to GPT-5.4 ($5 vs. $2.50 per 1M input tokens, and $25 vs. $15.00 per 1M output tokens, April 2026), which makes the average per-task cost higher compared to GPT-5.4 ($2.37 vs. $6.09). Overall, the first 50 steps cost delivers 82% accuracy and the next 50 steps delivers 3–4 additional points.
What do we learn?
The first lesson is less can be more. As model capabilities improve, heavily engineered web agent harnesses become less helpful and more constraining. A promising direction is to lean instead on something closer to a terminal. Rather than fixing the agent to a single rigid loop, a terminal-style harness gives the agent room to choose its own path through the problem space by writing any necessary code snippets, capturing and inspecting screenshots any time only when it is needed, and producing a script that is reusable for the task.
Code is emerging as a powerful interface for computer-use agents, offering robustness, efficiency, and reusability that low-level action spaces struggle to match. When an agent can express a task as a script, it sidesteps the brittleness of pixel-level interaction and produces artifacts that can be inspected, reused, and composed. Yet low-level actions — clicks, types, scrolls — retain a higher level of generality. They work everywhere a human can work: across websites and apps. Whenever an environment is hard for high-level abstraction, falling back to perception-and-action primitives is what keeps an agent functional.
One of the most compelling advantages of code as an action space is that scripts can be saved, indexed, and reused. Common patterns — filling a form, picking a date, making a reservation — need not be rediscovered on every task. An agent that builds up a library of validated scripts can amortize the cost of figuring out a workflow once and then execute it cheaply many times over, with predictable behavior and far lower latency than a fresh perception-driven attempt. Over time, this turns episodic problem-solving into a continuous learning capability. That, however, comes with real maintenance costs. A script index is only as useful as it is current, which means agents need mechanisms for validating scripts before reuse, detecting silent failures, and updating or retiring ones that no longer work. Another challenge is deciding the right granularity for these scripts. Too fine-grained, and the script library fragments into thousands of micro-routines that are individually reliable but not as useful. Too coarse-grained, and each script becomes a monolith tightly coupled to the exact task it was first written for. We expect agents to operate fluidly across both code and low-level action spaces — using code, especially cached and validated scripts, for common structured steps, and falling back to low-level actions when the environment is novel, unstable, or simply not accessible via code.
A broader lesson is that web-agent research is now benefiting from infrastructure originally designed for accessibility. Accessibility trees, ARIA metadata, and semantic page representations help assistive technologies expose web content to people with disabilities; today, the same signals also give LLM agents a machine-readable view of pages beyond pixels. As builders, we have a responsibility to bring these advances back to the accessibility community. Webwright could support everyday assistive workflows such as forms, appointments, transportation, and service comparison, while also acting as a repair layer for the web itself: inspecting pages, detecting missing labels, confusing controls, broken navigation, or inaccessible forms, and generating reusable scripts or overlays that make sites easier to understand and operate. In this sense, stronger web agents can help move us closer to a more accessible and useful web for everyone.