

在跨模态表征学习中,将不同模态的信号映射至统一的共享表示空间,进而驱动检索、理解与生成等一系列下游任务,是其核心目标。
而文本在所有模态中具有天然的独特性。它不仅是一种输入信号,更是人类对世界进行结构化认知、梳理概念体系以及开放世界知识的载体。正因为此,文本监督的质量,往往决定了跨模态表征空间的上限。更强大的文本监督信号能够引导模型在对齐过程中,学习到更复杂、更细粒度,也更具语义结构的表征空间。
如何系统性地释放语言所蕴含的知识潜力,并将其有效转化为跨模态表征能力,是近年来多模态研究中的关键问题之一。围绕这一挑战,学术界开始重新审视语言模型在跨模态学习体系中的定位与作用。
在 AAAI 2026 大会上,微软亚洲研究院提出的 LLM2CLIP 荣获了 Outstanding Paper Award(杰出论文奖)。这一成果不仅在工程实践上显著突破了 CLIP (Contrastive Language–Image Pretraining,语言-图像对比预训练) 的长期瓶颈,也在理论层面重新定义了语言在跨模态学习中的角色定位。

图1:微软亚洲研究院提出的 LLM2CLIP 荣获 AAAI 2026 杰出论文奖
LLM2CLIP: Powerful Language Model Unlocks Richer Cross-Modality Representation
论文链接:https://arxiv.org/pdf/2411.04997 (opens in new tab)
代码&模型链接:https://microsoft.github.io/LLM2CLIP/ (opens in new tab)
CLIP 的成功与隐忧:文本能力正在成为跨模态的“天花板”
CLIP 是发表于2021 年的一项里程碑式的工作。通过在海量图文对上进行对比学习,CLIP首次系统性地构建了统一的文本–视觉跨模态语义空间,奠定了其作为多模态基础模型的地位,并被广泛用于图像理解、跨模态检索、多模态大模型(VLLM)以及文生图扩散模型等前沿系统中。
然而,随着应用场景不断拓展,CLIP 范式中一个深层限制逐渐显现了出来——文本能力的滞后,成为跨模态系统性能进一步提升的“天花板”。
这一瓶颈主要体现在以下三个方面:
- 文本上下文窗口极窄:
CLIP 的文本编码器通常仅支持 77 个 token,超出的部分会被截断,这导致它在处理真实世界中常见的长文本、复杂描述和多实体关系时,往往显得力不从心。
- 文本编码器容量有限
CLIP 的 文本编码器(text encoder) 参数量通常只有视觉编码器的十分之一左右。由于文本编码器是与视觉编码器同步从零开始训练的,所以这种有限的容量使其难以充分吸收丰富的语言知识。
- 文本先验利用效率低下
与大语言模型(LLMs)相比,CLIP 的文本建模能力在语义理解、知识覆盖和推理能力上均存在显著差距。由于缺乏深厚的语言先验,模型在理解复杂指令和抽象概念时表现不佳。
直观来看,更强的文本理解能力理应带来更通用的跨模态表征。但这中间的真正挑战在于:如何在不重新进行昂贵的大规模预训练的前提下,把大语言模型的能力高效地引入到 CLIP之中?
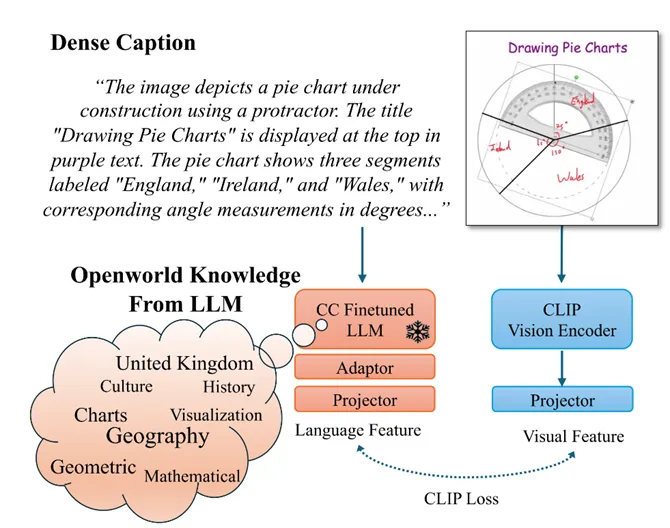
图2:LLM2CLIP 方法框架示意图,通过引入经 Caption-Contrastive 微调的大语言模型,为 CLIP 构建更具判别性的文本表征空间
一个看似直接的思路是,用大语言模型直接替换 CLIP 的文本编码器。然而,实验结果却几乎一致地指向失败。根本原因在于,LLMs 本质上是 Decoder-only 的生成模型,其输出特征并非为度量学习(Metric Learning)而设计的。
在跨模态对齐任务中,原始 LLMs 生成的文本特征难以清晰地区分语义相近但指向不同图像的描述,这种“模糊表征”会直接破坏图文对齐所需的判别性结构,导致训练效果断崖式下跌。这揭示了一个关键事实,LLMs 并非天然适配跨模态对齐的嵌入(embedding) 模型。

图3:Caption-Contrastive微调显著提升了 LLMs 对相似图像描述的区分能力,为高质量图文对齐奠定了基础
先赋予 LLMs “判别性”,再进行跨模态对齐
针对上述瓶颈,微软亚洲研究院的研究员们提出了 LLM2CLIP,旨在通过将大语言模型引入 CLIP 训练流程中,从而系统性提升跨模态表征能力。AAAI 2026评审对LLM2CLIP给出高度评价的原因之一就是LLM2CLIP并未停留在“更大的模型”上,而是精准击中了跨模态学习中一个长期被忽视的结构性问题。
研究员们为LLM2CLIP 设计了一套精准的两阶段训练策略:
第一阶段:Caption-to-Caption 对比学习,重塑文本嵌入空间
在图文对齐之前,研究员们首先对 LLMs 进行了 caption-to-caption 的对比学习微调。通过引入高质量的图像描述 (caption) 数据,引导 LLMs 在嵌入空间中精准捕捉语义间的细微差别,从而有效区分那些语义相近但指向不同图像的文本描述。
这一阶段的训练至关重要。它显著增强了 LLMs 在 caption 检索任务中的判别能力。实验证实,若跳过此步骤直接使用 LLMs 进行 CLIP 微调,模型将因无法收敛到有效的判别空间而导致性能严重退化。
这一步成功驱动了 LLM s从“生成模型”转变为一个适合跨模态学习的文本嵌入模型,为后续的图文对齐夯实了文本底座。
第二阶段:高效的 LLM–视觉编码器对齐
获得经过 caption 对比学习的 LLMs 后,研究员们将其与 CLIP 的视觉编码器重新进行跨模态对齐:
- 采用与原始 CLIP 相同的对比学习目标(InfoNCE / Sigmoid Loss)
- 彻底抛弃原有的 CLIP 文本编码器
- 冻结 LLMs 主体,仅通过一个轻量适配器( adaptor)模块实现文本特征向跨模态空间的映射
- 对视觉编码器进行微调
两阶段的设计为 LLM2CLIP 带来了显著的工程优势。由于 LLMs 可以在计算过程中完全 offload(卸载),所以整体训练的显存和计算开销被压低至与原始 CLIP 微调几乎相当的水平。
以搭载 8B 参数的大语言模型的实验配置为例。LLM2CLIP实现了13 倍的训练速度飞跃,显存占用大幅缩减为原来的 1/20,而且还可以在有限设备上部署更大规模的批量处理( Batch Size),这种规模效应反而反哺了模型的性能。
少量数据,显著收益:打破对“大规模预训练”的路径依赖
传统 CLIP 范式高度依赖于海量数据,其文本编码器往往需要经历约 40B 级别图文对的预训练。然而,在引入 LLMs 后,研究员们发现,仅需使用 3–15M 的图文数据重新对齐,即可在性能上全面超越原始模型。
在与工业级 SOTA 模型 SigLIP-2 的对比实验中,LLM2CLIP展现出了显著的增长潜力:
- 英文短文本检索:稳步提升 +1.0 / +1.9
- 英文长文本检索:实现 +14.8 / +15.8 的突破性跨越,解决了 CLIP 的“长文本恐惧症”。
- 中文 COCO-CN:提升 +15.5 / +18.5%
- XM3600(36 种语言):均分提升 +11.9 / +15.2
值得注意的是,LLM2CLIP 的跨模态对齐过程完全基于英文数据,但其展现出的多语言能力却实现大幅飞跃,这体现了 LLMs 语言先验的强泛化性。
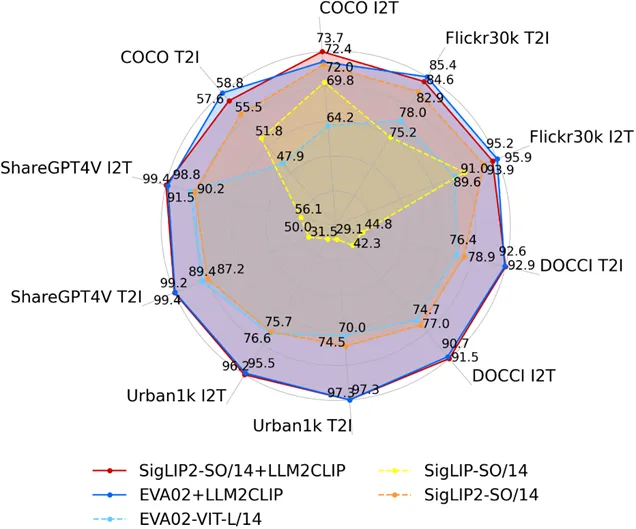
图4:LLM2CLIP 在多项图文检索基准上稳定提升性能,包括在 SigLIP2 等工业级跨模态模型上的表现。
不止于跨模态:视觉编码器的深度进化
实验数据表明,引入 LLMs 后,文本监督信号变得更加细粒度和结构化,反向驱动了视觉编码器的自我进化:
- 在零样本(zero-shot)及有监督设置下的目标检测与图像分割任务上,均取得了稳健的性能增长;
- 在 ImageNet linear probing 测试中表现更优;
- 在完全剥离文本编码器的纯视觉场景下,视觉表征能力也显著增强。
为了进一步验证LLM2CLIP的潜力,研究员们将 LLaVA-1.5 中的原始视觉编码器替换成了 LLM2CLIP 训练后的 ViT-L 版本。在超过 87.5% 的多模态基准测试中,模型性能实现了全面跃升,仅在极少数任务上有轻微下降。这表明 LLM2CLIP 不仅重塑了跨模态空间,更为复杂的视觉理解与推理任务奠定了一个更加坚固的视觉根基。
LLM2CLIP 的价值并不只体现在性能的数字上,还有其方法论的意义:
- 它从底层解决了 CLIP 长期存在的文本建模短板,彻底打破了上下文长度和文本理解能力的瓶颈;
- 它提出了一种高效、可扩展且工程友好的 LLMs 引入方式,在几乎不增加训练成本的前提下,实现了模型跨模态性能的跃升;
- 它全面增强了包括工业级 SOTA(如EVA02, SigLIP-2)在内的 CLIP 系列模型,其影响力覆盖了跨模态检索、多语言理解和视觉任务等场景。
研究员们认为,语言不应仅被视作多模态系统的一个输入模态,而应进阶为引导跨模态表征学习的“知识中枢”。
通过更深层地挖掘和引入人类语言中的先验知识,未来的多模态模型将能够建立起对真实世界更深邃的洞察,从而支撑起更复杂、更多样、具有更高价值的应用场景。