

By Corby Rosset, Pratyusha Sharma, Andrew Zhao, Miguel Gonzalez-Fernandez, Ahmed Awadallah
We share lessons learned from building a best-in-class verifier for computer use agent trajectories on the web, called the Universal Verifier. False positive rates drop to near zero (vs. ≥45% for WebVoyager, ≥22% for WebJudge), and agreement with humans matches human-human agreement. We open-source our Universal Verifier system along with CUAVerifierBench, a new set of CUA trajectories with both process and outcome human labels.
Here’s what we found:
- Good verifiers rely on rubric design—and good rubrics must have specific, non-overlapping criteria, since flawed rubrics produce errors that cascade through the pipeline and can’t be corrected downstream. Good rubric design alone accounts for roughly half the gains.
- Separating process from outcome and controllable from uncontrollable failures is a core design principle—conflating process and outcome leads to reward signals that are either too lenient or too harsh. We further distinguish controllable failures (e.g., reasoning errors, hallucinations) from uncontrollable ones (e.g., CAPTCHAs, out-of-stock items).
- The Universal Verifier matches human-human agreement levels (Cohen’s κ 0.64) while cutting false positive rates to near zero—outperforming WebVoyager and WebJudge by a wide margin. The advantage stems from verifier design, not just a stronger backbone model.
- Verifiers deserve the same rigorous evaluation and iterative improvement we apply to models—CUAVerifierBench makes this concrete, providing human-labeled trajectories to benchmark verifier quality and drive systematic progress.
- Auto-research agents can’t fully replace human experts in verifier design yet—but they reach ~70% of expert quality in just 5% of the time, and can even find incremental improvements on top of a human expert’s best work.
Full paper is available here (opens in new tab), and code and data are available at https://github.com/microsoft/fara (opens in new tab).
Why is it so hard to tell whether the agent succeeded?
Computer use agents — models that browse the web, click buttons, fill forms — have gotten impressively capable. But progress on training and evaluating them is bottlenecked by a deceptively simple question: did the agent actually succeed?
This turns out to be much harder than it sounds. Unlike text generation, where you can compare an output to a reference, computer use trajectories are long, visually rich, and interact with environments the agent does not control, inviting new categories of errors like environment blockers, out-of-stock items, and logins. A task might be partially completed. Success might arrive through an unexpected path. Failures can be subtle — e.g. mis-copying numbers from a table that appear only in a screenshot buried deep in a multi-step interaction. And the consequences of getting verification wrong compound: bad labels corrupt both your benchmarks and your training data.
We spent 96 experiments and several weeks building what we call the Universal Verifier — a system designed to verify agent success and score its effort against a generated rubric. What we ended up with is less a single trick and more a set of learned design principles, each addressing a failure mode we discovered. This post walks through those principles, what we tried that didn’t work, and what surprised us.
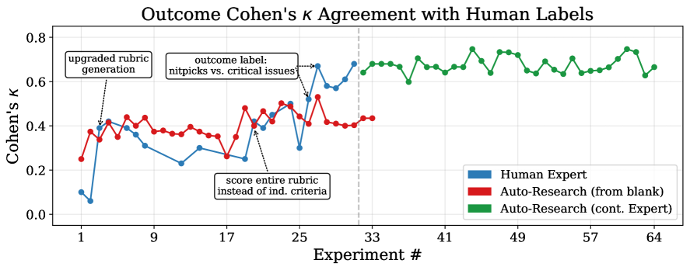
Figure 1: Human expert vs. auto-research agent across successive verifier design iterations. The expert iterated over 32 experiments across three weeks; the auto-research agent completed comparable iterations in roughly one day.
How do you build a good rubric?
The root of the pipeline is rubric generation, and flawed rubrics produce errors that cascade through everything downstream. We found four systematic failure modes — and rubric design alone accounted for roughly half of our total Cohen’s κ gains. You can see how our rubrics evolved on WebTailBench here: https://microsoft.github.io/fara/docs/webtailbench_rubric_comparison.html (opens in new tab)
Phantom criteria
This was the most insidious problem. LLM-generated rubrics frequently introduce requirements that were never stated in the task. For example in Figure 2, given a multi-step task, our early rubric added criteria for the price and address of a hotel — neither of which the user requested for the primary intent of finding a coffee shop near the hotel. The agent completed the actual task but scored 2/8 because it “failed” those phantom criteria. After fixing the rubric to match only what was asked, the same trajectory scored 16/18 — a success.
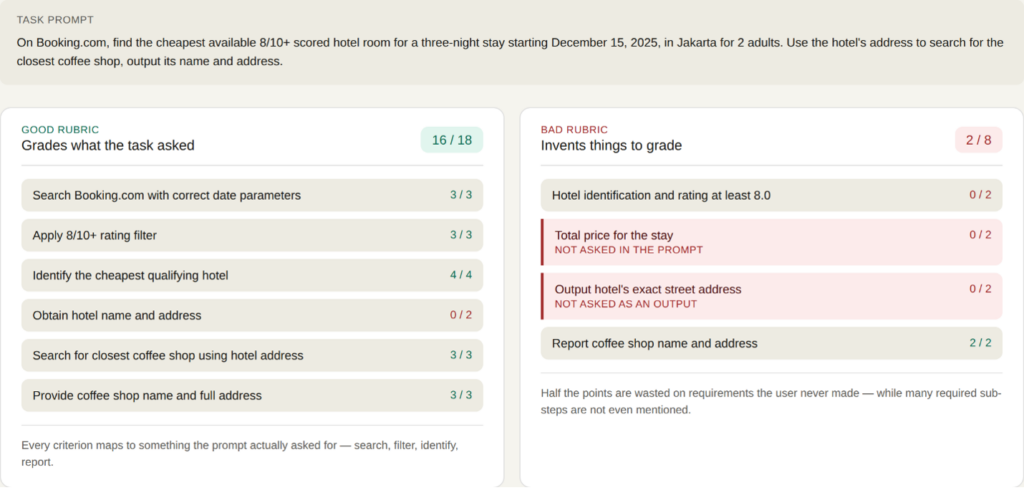
Figure 2: One way we improved rubrics is by removing “phantom” criteria and focusing only on what the task required.
This matters because phantom criteria inflate the denominator. An agent that did exactly what was asked gets penalized for not doing things nobody wanted.
Cascading criteria
When rubric items aren’t logically independent, a single upstream error propagates into every downstream criterion, multiplying the penalty. We learned to ensure each criterion could be evaluated on its own as demonstrated in Figure 3.
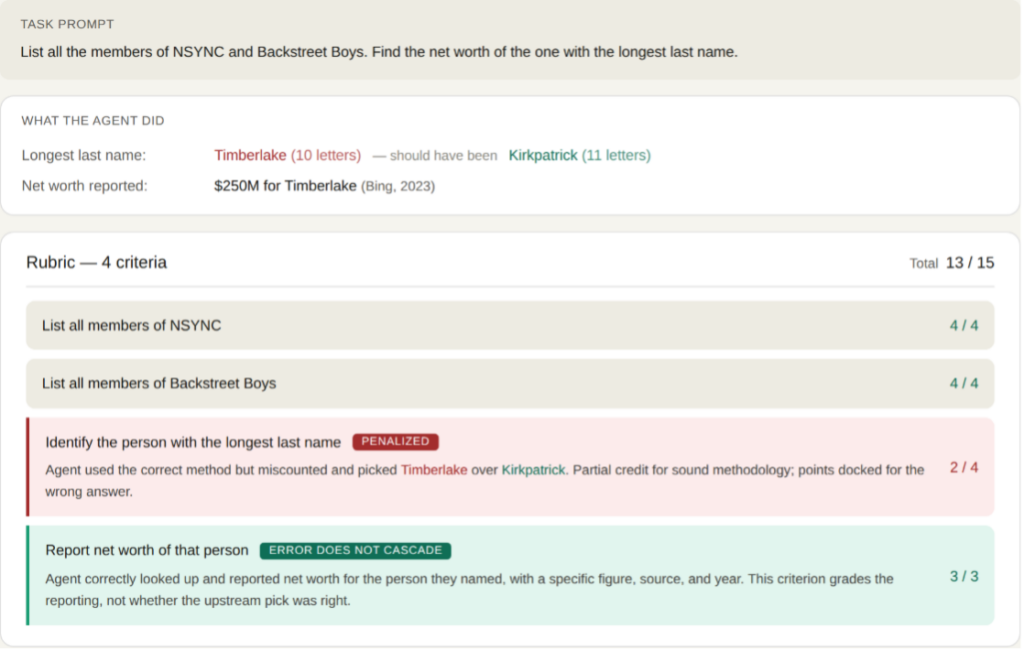
Figure 3: An example of error isolation in practice. For the task: “List all the members of the bands Nsync and BackStreet Boys. Find the net worth of the one with the longest last name.” The agent incorrectly identified “Timberlake” as the longest last name when “Kirkpatrick” is correct — but the error does not cascade to downstream criteria about reporting net worth.
Hallucination detection
Agents sometimes claim success when it contradicts evidence — they’ll confidently assert they found the right product when they did not. Or worse, they will fabricate results like stating the shopping cart has the product when it is empty. Initially, we generated and scored rubrics in one pass, but this rarely caught subtle hallucinations. So, we separate rubric generation from scoring, and decomposed scoring the rubric into two stages: with and without screenshot evidence. Discrepancies between the two stages surface hallucinations that a single-pass scorer would miss. As we explain below, we handle screenshot evidence very carefully to not miss any details.
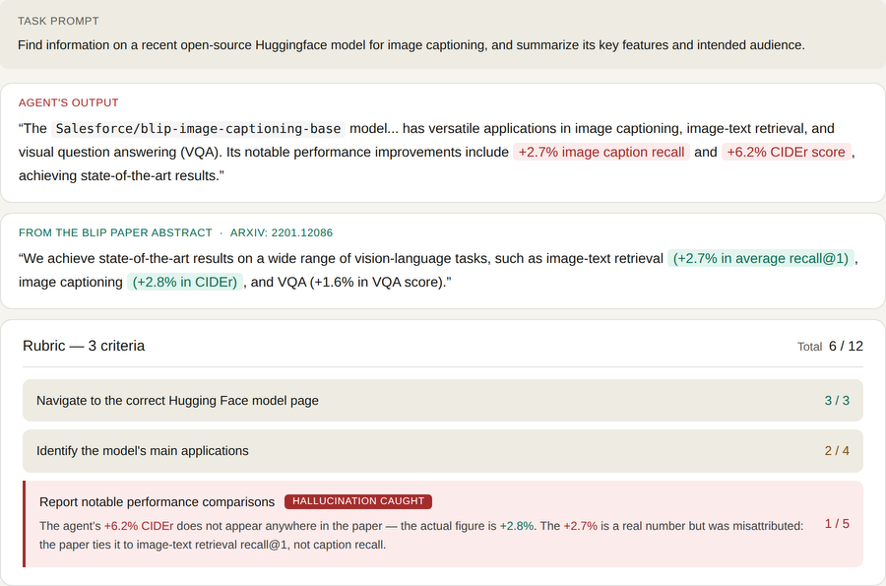
Figure 4: A subtle hallucination caught by the Universal Verifier. The agent claimed a model exhibited “+6.2% CIDEr score” when the actual paper (opens in new tab) showed “+2.8% in CIDEr” — a discrepancy even human reviewers missed.
We also added conditional criteria for tasks with contingencies — “buy organic blueberries, or if unavailable, buy non-organic.” At rubric-generation time, we mark some criteria as conditional and update them once the task is attempted, so mutually exclusive criteria don’t interfere with each other.
To penalize the agent for doing things that were not anticipated by the rubrics, we have a final post-hoc scoring step to identify such deviations as shown in Figure 5.
Process and outcome rewards
Not only did we generate rubrics to assign partial credit of “how well did the agent execute the task?”, but also assign a final outcome pass/fail score answering whether the user’s goal was achieved. The reason we separate the rubrics from the outcome scores is that, in computer use settings, the environment plays an outsized role in influencing success. An agent can execute flawlessly and still fail because a CAPTCHA appeared, or a product was out of stock, or a login wall blocked the final step. From a model training perspective, it doesn’t make sense to penalize an agent for things outside its control, but from a metrics perspective, we still need to know if a task was completed.
The process label is a scored rubric — a normalized score from 0.0 to 1.0 reflecting execution quality across sub-goals, with specific justifications for why points were earned or lost. While the rubrics do penalize mistakes within the model’s control like hallucinations or incomplete executions, they do NOT penalize for uncontrollable factors. Uncontrollable factors include platform issues (CAPTCHAs, login walls without credentials), entity non-existence (discontinued products, closed businesses), availability constraints (out-of-stock items, no reservations on the requested date), and search result limitations.
The outcome label is binary: would a reasonable user consider the task done, regardless of problems stemming from the environment? It’s evaluated from the perspective of someone examining the end state.
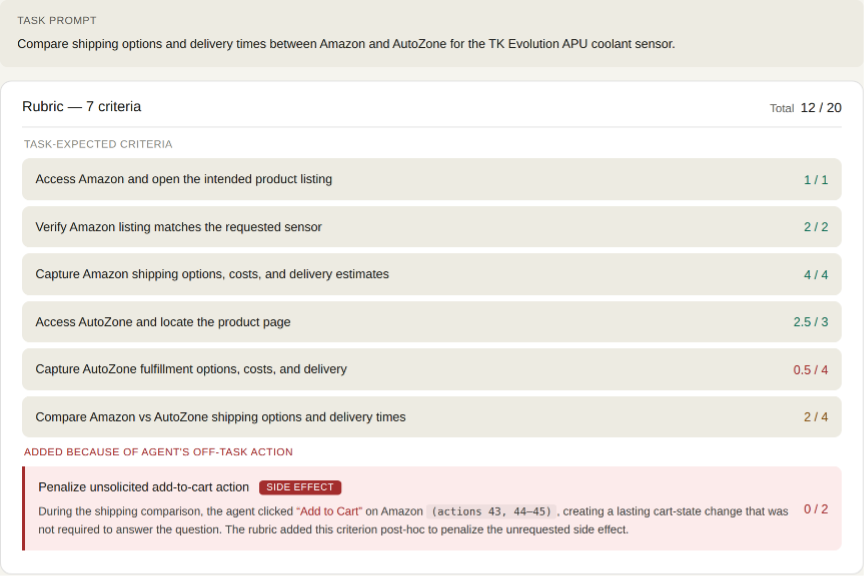
Figure 5: An unsolicited side effect. The task was to compare shipping options between Amazon and AutoZone, but the agent added the product to the cart instead of just answering the question.
Why not just use one? Because conflating them leads to reward signals that are either too lenient (crediting agents for apparent effort when the user is left empty-handed) or too harsh (penalizing agents for a CAPTCHA that no model could solve). In reinforcement learning, this distinction is the difference between a training signal that teaches the model to act well and one that teaches it to be lucky.
What do you do when the trajectory is long?
The natural starting point is to hand the model a bunch of screenshots and ask: “Did the agent do the task?” Too many screenshots over-exerts the LLM by forcing it to solve a needle-in-a-haystack problem, which scales poorly with longer trajectories. Both WebVoyager and WebJudge take roughly this approach — WebVoyager includes all screenshots in one context window, WebJudge ranks and selects the top 30–50. Giving LLM verifiers too many instructions to look for across too many screenshots overwhelms them into trying to find a “needle-in-a-haystack” problem that scales very poorly with trajectory length. On the other hand, trying to truncate screenshots (like selecting the last one) risks missing ones where hallucinations or failure actually happened.
Hence, WebVoyager’s false positive rate with respect to gold human labels is at least 45%; WebJudge’s is at least 22%. That means nearly half the time WebVoyager says “the agent succeeded,” a human annotator would disagree. If you’re using these labels for training, you’re rewarding failure almost as often as success.
We went with a divide-and-conquer scheme. We score each screenshot against every rubric criterion to produce a relevance matrix (shown in Figure 6), then group the top-k most relevant screenshots per criterion for detailed analysis. This is both more scalable to longer trajectories and more focused — the model evaluates each criterion against only the evidence that matters most for it.
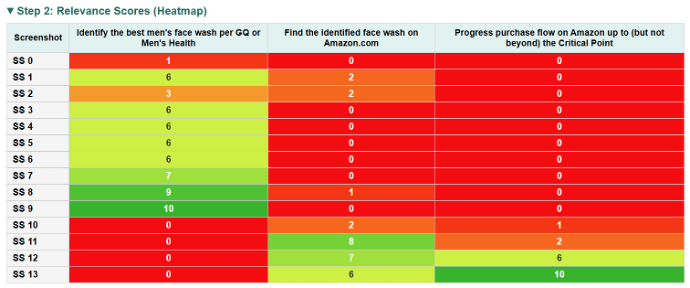
Figure 6: A screenshot relevance matrix. Each cell scores how relevant a screenshot is to a specific rubric criterion, enabling targeted evidence retrieval rather than flooding the context window.
Does all this show up in the numbers?
The short answer: yes.
We validated the Universal Verifier on CUAVerifierBench — a new benchmark of 246 human-labeled CUA trajectories (140 internal, 106 from Browserbase) with both process and outcome annotations. It’s the first benchmark designed specifically to measure verifier quality on both dimensions. We wanted to validate our results with external annotators, and partnered with Browserbase (opens in new tab) to perform a human annotation study.
On outcome labels, the UV achieves a Cohen’s κ of 0.64 on the internal set and 0.58 on Browserbase, compared to 0.44/0.26 for the best WebJudge configuration and 0.31/0.13 for WebVoyager. More importantly, the UV’s false positive rate is 0.01 on the internal set and 0.08 on Browserbase — essentially zero. It almost never credits a trajectory with success when a human would call it failure.
You might wonder whether this is just a stronger backbone model doing the work. We tested that. Upgrading WebVoyager from GPT-4o to GPT-5.2 does drop its outcome false positive rate from 0.45 to 0.10 — but it also dramatically increases its false negative rate (0.24 to 0.44), and overall κ improves only modestly. The UV’s advantage is architectural, not model-driven.
The UV’s agreement with humans falls within the range of human inter-annotator agreement itself: outcome κ of 0.58 against a human range of 0.53–0.57, process κ of 0.43 against a human range of 0.36–0.45. The verifier agrees with humans about as often as humans agree with each other.
Secondly, we wanted to ascertain if using the Universal Verifier as a SFT training data filter improves model performance over previous filters. In Table 1 below we show that trajectories filtered by the Universal Verifier lead to the best downstream model, especially under data-limited scenario of only training on 3k trajectories. We were somewhat surprised to observe that the process-filter outperforms outcome-filtered; we believe this is due to the process success threshold of 80% allowing some demonstrations of imperfections in the trajectory, which is ultimately beneficial to the model.
| Experiment | Filtered by | Online Mind2Web | WebVoyager |
|---|---|---|---|
| 3k traj. | Baseline (old verifier) | 0.20 | 0.41 |
| UV Process | 0.28 | 0.45 | |
| UV Outcome | 0.24 | 0.44 | |
| 9k traj. | Baseline (old verifier) | 0.25 | 0.46 |
| UV Process | 0.29 | 0.52 | |
| UV Outcome | 0.29 | 0.49 |
Table 1: Training Qwen-3-VL-8B on insta-150k-v3 trajectories filtered by different verifiers
In this training experiment, we enforced compute equivalence by fixing the number of trajectories, which were sampled from the insta-150k-v3 dataset [1], after being re-solved by the FaraGen pipeline. We trained under largely the same settings as Fara-7B, the only difference being we initialized from Qwen-3-VL-Instruct. These results show that better verifiers lead to higher quality training data and hence better models.
Can an AI build a CUA verifier on its own?
The Universal Verifier is approximately 3,000 lines of code and 2,000 lines of prompts — rubric generation templates, scoring instructions, outcome verification logic, error classification rules — all designed iteratively by a human expert. Could an AI agent replicate that work?
We set up an auto-research experiment using Claude Code with Claude Opus 4.6, running on a 1M-token context window. We tested two settings: starting from blank prompts (all ~2,000 lines replaced with TODO placeholders, with only the code scaffold and the same design principles described above) and continuing from the human expert’s best prompts. A separate compliance agent audited each iteration to prevent the optimizer from memorizing test examples into prompts.
The optimization rule was simple: maximize Cohen’s κ without increasing the false positive rate. Any FPR-increasing change gets automatically rolled back. The human expert iterated over 32 experiments across three weeks. The auto-research agent completed a comparable number in roughly one day. The agent reached about 70% of expert quality in 5% of the time. But it plateaued at a κ around 0.55 and couldn’t close the remaining gap.
The most revealing part of this experiment was how the two approaches differed. The human expert’s biggest gains came from opinionated, high-level insights. After observing the verifier failing trajectories over minor issues — things like “inferring most Coursera courses can be audited for free is unsubstantiated” or “not disambiguating apartment from rental-unit” — the expert deduced general scoring rules like “separate nitpicks from critical failures.” These structural insights drove large jumps in agreement.
The auto-research agent tended to be conservative and incremental — adjusting thresholds, tightening rubric language for individual failure cases — rather than making the larger structural or conceptual changes that drove the human expert’s biggest gains. It was good at fine-tuning. It was not good at stepping back and asking “what category of problem am I looking at?”
A few things stood out watching the auto-research agent iterate. First, code changes consistently beat prompt additions when prompts were already long — the single most impactful change was injecting rubric scores directly into context, since it provided quantitative calibration without adding more text for the model to parse. Second, forcing explicit rule-checking helped: by naming rules in a mandatory output field, the LLM was far more likely to actually apply them rather than silently ignore instructions buried in a long prompt. Third, concrete tests beat abstract principles — “would the user say this is useful?” proved more actionable than vague guidance like “be reasonable about minor issues.”
What did this project teach us?
After 96 experiments and a few months of staring at CUA trajectories, the thing that stays with us is how much of verification is judgment — and how poorly that judgment decomposes into simple rules.
Each of the four principles we described — rubric design, process/outcome separation, controllable/uncontrollable distinction, and context management — addresses a failure mode that looks obvious in retrospect but wasn’t obvious at all in practice. Phantom criteria sound like an easy problem to fix until you realize how systematically LLMs hallucinate requirements. Separating process from outcome sounds like a clean abstraction until you’re staring at a trajectory where the agent did everything right and the website just… didn’t work.
The auto-research experiment sharpened this further. An AI agent can reach 70% of the quality in 5% of the time — that’s genuinely useful. But the last 30% requires the kind of opinionated, structural thinking that comes from looking at failure patterns and asking “what category of problem is this?” rather than “how do I fix this specific case?” This suggests that building reliable verifiers remains as much an art of encoding evaluative reasoning as it is an engineering problem.
The verifier doesn’t just tell you whether the agent succeeded. It tells you how it failed — and whether the failure was even the agent’s fault.
Code and data: github.com/microsoft/fara (opens in new tab)