



Excerpt: CTI-REALM is Microsoft’s open-source benchmark for evaluating AI agents on real-world detection engineering—turning cyber threat intelligence (CTI) into validated detections. Instead of measuring “CTI trivia,” CTI-REALM tests end-to-end workflows: reading threat reports, exploring telemetry, iterating on KQL queries, and producing Sigma rules and KQL-based detection logic that can be scored against ground truth across Linux, AKS, and Azure cloud environments.
Security is Microsoft’s top priority. Every day, we process more than 100 trillion security signals across endpoints, cloud infrastructure, identity, and global threat intelligence. That’s the scale modern cyber defense demands, and AI is a core part of how we protect Microsoft and our customers worldwide. At the same time, security is, and always will be, a team sport.
That’s why Microsoft is committed to AI model diversity and to helping defenders apply the latest AI responsibly. We created CTI‑REALM and open‑sourced it so the broader industry can test models, write better code, and build more secure systems together.
CTI-REALM (Cyber Threat Real World Evaluation and LLM Benchmarking) is Microsoft’s open-source benchmark that evaluates AI agents on end-to-end detection engineering. Building on work like ExCyTIn-Bench, which evaluates agents on threat investigation, CTI-REALM extends the scope to the next stage of the security workflow: detection rule generation. Rather than testing whether a model can answer CTI trivia or classify techniques in isolation, CTI-REALM places agents in a realistic, tool-rich environment and asks them to do what security analysts do every day: read a threat intelligence report, explore telemetry, write and refine KQL queries, and produce validated detection rules.
We curated 37 CTI reports from public sources (Microsoft Security, Datadog Security Labs, Palo Alto Networks, and Splunk), selecting those that could be faithfully simulated in a sandboxed environment and that produced telemetry suitable for detection rule development. The benchmark spans three platforms: Linux endpoints, Azure Kubernetes Service (AKS), and Azure cloud infrastructure with ground-truth scoring at every stage of the analytical workflow.
Why CTI-REALM exists
Existing cybersecurity benchmarks primarily test parametric knowledge: can a model name the MITRE technique behind a log entry, or classify a TTP from a report? These are useful signals. However, they miss the harder question: can an agent operationalize that knowledge into detection logic that finds attacks in production telemetry?
No current benchmark evaluates this complete workflow. CTI-REALM fills that gap by measuring:
- Operationalization, not recall: Agents must translate narrative threat intelligence into working Sigma rules and KQL queries, validated against real attack telemetry.
- The full workflow: Scoring captures intermediate decision quality—CTI report selection, MITRE technique mapping, data source identification, iterative query refinement. Scoring is not just limited to the final output.
- Realistic tooling: Agents use the same types of tools security analysts rely on: CTI repositories, schema explorers, a Kusto query engine, MITRE ATT&CK and Sigma rule databases.
Business Impact
CTI-REALM gives security engineering leaders a repeatable, objective way to prove whether an AI model improves detection coverage and analyst output.
Traditional benchmarks tend to provide a single aggregate score where a model either passes or fails but doesn’t always tell the team why. CTI-REALM’s checkpoint-based scoring answers this directly. It reveals whether a model struggles with CTI comprehension, query construction, or detection specificity. This helps teams make informed decisions about where human review and guardrails are needed.
Why CTI-REALM matters for business
- Measures operationalization, not trivia: Focuses on translating narrative threat intel into detection logic that can be validated against ground truth.
- Captures the workflow: Evaluates intermediate steps (e.g., technique extraction, telemetry identification, iterative refinement) in addition to the final rule quality.
- Supports safer adoption: Helps teams benchmark models before considering any downstream use and reinforces the need for human review before operational deployment.
Latest results
We evaluated 16 frontier model configurations on CTI-REALM-50 (50 tasks spanning all three platforms).
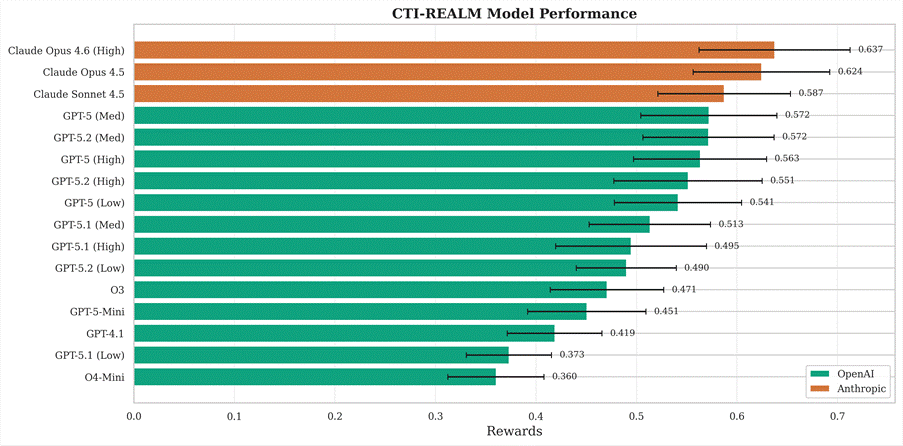
What the numbers tell us
- Anthropic models lead across the board. Claude occupies the top three positions (0.587–0.637), driven by significantly stronger tool-use and iterative query behavior compared to OpenAI models.
- More reasoning isn’t always better. Within the GPT-5 family, medium reasoning consistently beats high across all three generations, suggesting overthinking hurts in agentic settings.
- Cloud detection is the hardest problem. Performance drops sharply from Linux (0.585) to AKS (0.517) to Cloud (0.282), reflecting the difficulty of correlating across multiple data sources in APT-style scenarios.
- CTI tools matter. Removing CTI-specific tools degraded every model’s output by up to 0.150 points, with the biggest impact on final detection rule quality rather than intermediate steps.
- Structured guidance closes the gap. Providing a smaller model with human-authored workflow tips closed about a third of the performance gap to a much larger model, primarily by improving threat technique identification.
For complete details around techniques and results, please refer to the paper here: [2603.13517] CTI-REALM: Benchmark to Evaluate Agent Performance on Security Detection Rule Generation Capabilities.
Get involved
CTI-REALM is open-source and free to access. CTI-REALM will be available on the Inspect AI repo soon. You can access it here: UKGovernmentBEIS/inspect_evals: Collection of evals for Inspect AI.
Model developers and security teams are invited to contribute, benchmark, and share results via the official GitHub repository. For questions or partnership opportunities, reach out to the team at msecaimrbenchmarking@microsoft[.]com.
CTI-REALM helps teams evaluate whether an agent can reliably turn threat intelligence into detections before relying on it in security operations.
References
- Microsoft raises the bar: A smarter way to measure AI for cybersecurity | Microsoft Security Blog
- [2603.13517] CTI-REALM: Benchmark to Evaluate Agent Performance on Security Detection Rule Generation Capabilities
- CTI-REALM: Cyber Threat Intelligence Detection Rule Development Benchmark by arjun180-new · Pull Request #1270 · UKGovernmentBEIS/inspect_evals




