


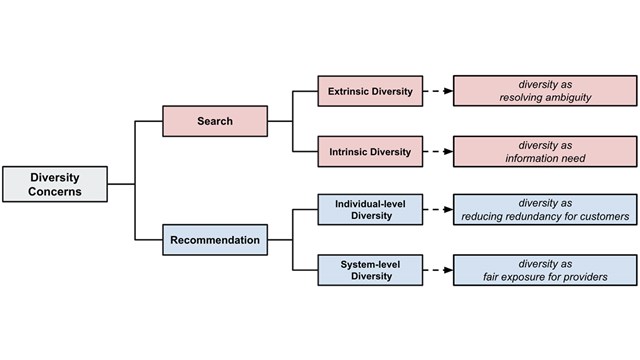
Search and information retrieval

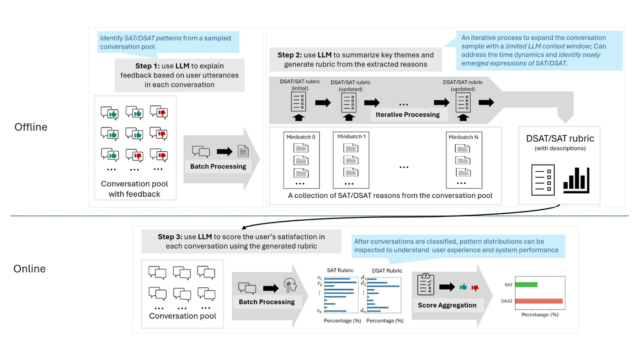
Project
Web crawl scheduling
A web crawler is an essential part of a search engine that visits URLs and downloads their content, which is subsequently processed, indexed, and used by the search engine to decide which results to show…
Publication
Overview of the TREC 2019 deep learning track
Publication
Towards a model for spoken conversational search
Publication