

近年来,图像生成模型的飞速发展令人瞩目。从早期的通用图像生成,到如今逐步迈向更具实用价值的视觉内容创作,这一领域正经历从“好看”到“好用”的关键跃迁。然而,在繁荣表象之下,一个核心挑战正日益凸显:现有主流评测基准仍以自然图像为主,缺乏面向商业设计场景的系统性评估,无法有效衡量模型在结构化和多重约束下的表现。
与通用图像相比,商业视觉文档往往包含高密度文本、复杂版式结构以及多种视觉元素的协同布局,其生成与评估的难度明显更高。这也使得“如何科学评估模型是否真正具备商业可用性”成为行业亟待回答的问题。
为了填补这一空白,微软亚洲研究院推出了 BizGenEval。这是首个面向商业视觉内容生成的系统性基准测试。该工作不仅为评估模型能力提供了全新的标尺,也为生成式 AI 迈向工业级商业落地指明了发展方向。
BizGenEval: A Systematic Benchmark for Commercial Visual Content Generation
论文链接:https://arxiv.org/abs/2603.25732 (opens in new tab)
项目主页:http://aka.ms/bizGenEval (opens in new tab)
代码与数据:https://huggingface.co/datasets/microsoft/BizGenEval (opens in new tab)
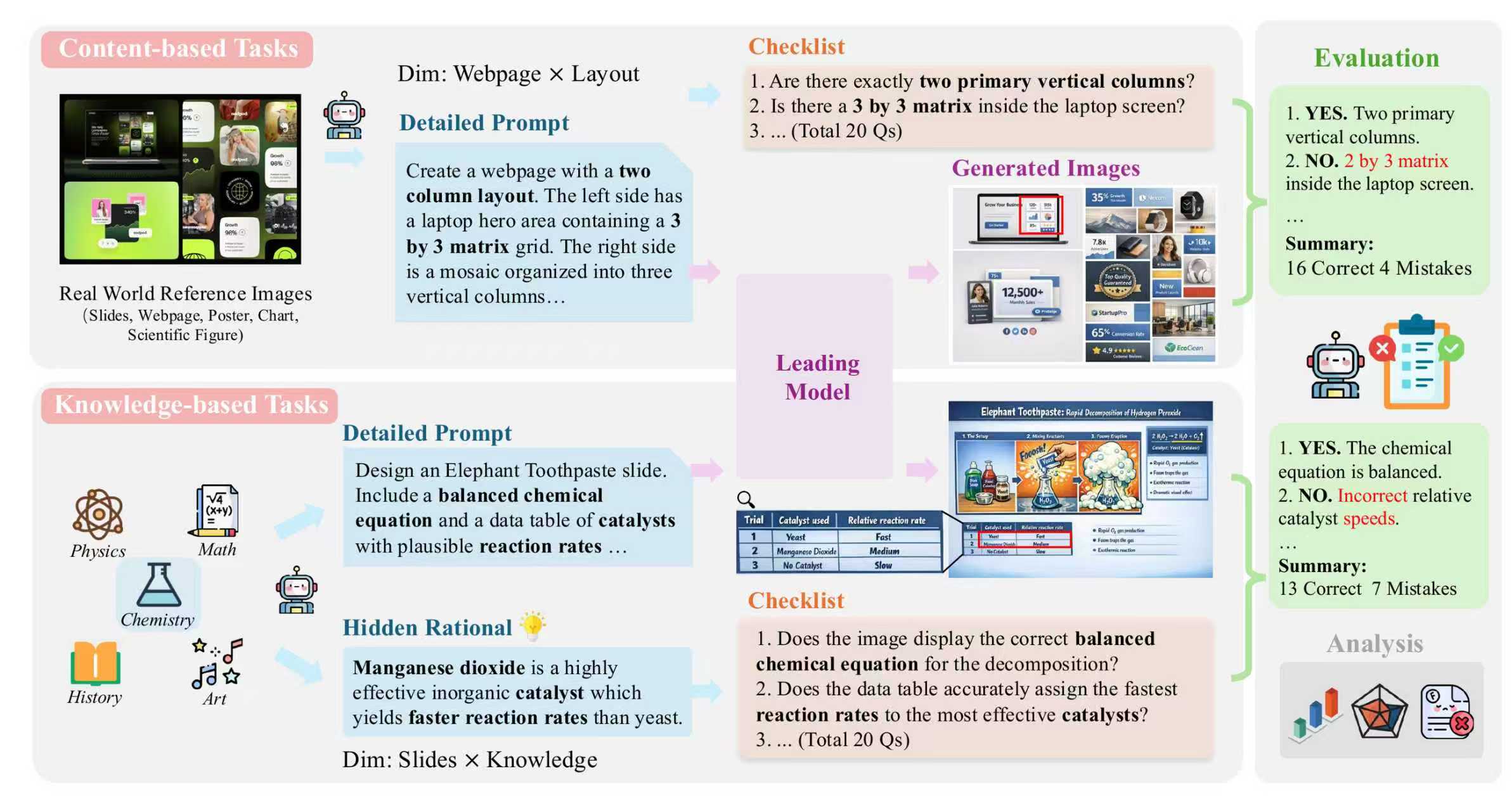
图1: BizGenEval数据构建与评测流程
真实场景 × 核心能力:构建商业视觉生成的系统评估框架
评估一个模型是否具备真正的商业价值,必须将其置于真实的商业语境中。BizGenEval 贴近实际行业需求,围绕典型商业使用场景,系统性地覆盖了五类具有代表性的视觉文档类型:
- 网页 (Webpages):包含结构化布局、文本和功能界面元素(如标题、分段、按钮等)的网页设计任务。
- 幻灯片 (Slides):用于报告、讲座和商业场景的演示文稿,具有层次结构、项目符号列表和对齐的视觉元素。
- 图表 (Charts):条形图、折线图等多系列图表,涉及数值、坐标轴和图例的精确渲染 。
- 海报 (Posters):结合排版、图形和布局设计的宣传或信息海报,强调视觉层次和构图平衡。
- 科学插图 (Scientific Figures):学术论文中的插图,包括图表、流程和说明,通过组件、箭头和注释形成清晰的结构 。
通过这五大核心题材的划分,BizGenEval 能够精准地总结各种前沿模型在不同商业应用领域下的生成能力,为行业应用落地提供最直观的参考。
仅关注“生成了什么”远远不够,更重要的是理解模型是“如何生成”的。为此,BizGenEval从能力本质出发,系统性构建了四个关键评估维度,为模型优化与演进提供清晰指引:
- 文本渲染 (Text Rendering):评估模型对不同类型文本内容的渲染能力,包括短标题、长段落、表格及其与其他组件的整合。
- 布局控制 (Layout Control):关注空间组织与结构的表达能力,涵盖整体布局、复杂流程结构,以及箭头、区块和元素的层次排列。
- 属性绑定 (Attribute Binding):考察模型对颜色、形状、样式、图标和数量等视觉属性的控制,强调对细粒度元素的把控。
- 基于知识的推理 (Knowledge-based Reasoning):测试模型的推理和领域知识,包括跨不同领域(如物理、化学、艺术、历史等)应用客观世界常识的能力 。
这四大能力维度与五类商业题材交叉组合,构成了 20 个多样化的评估任务,系统覆盖了商业视觉文档生成中的关键挑战与核心痛点,为模型能力评估提供了一套更加完整且具有实践指导意义的框架。

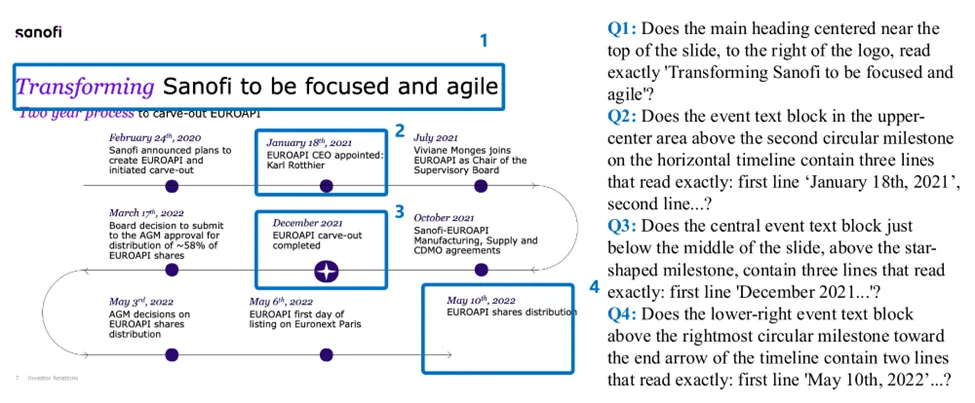
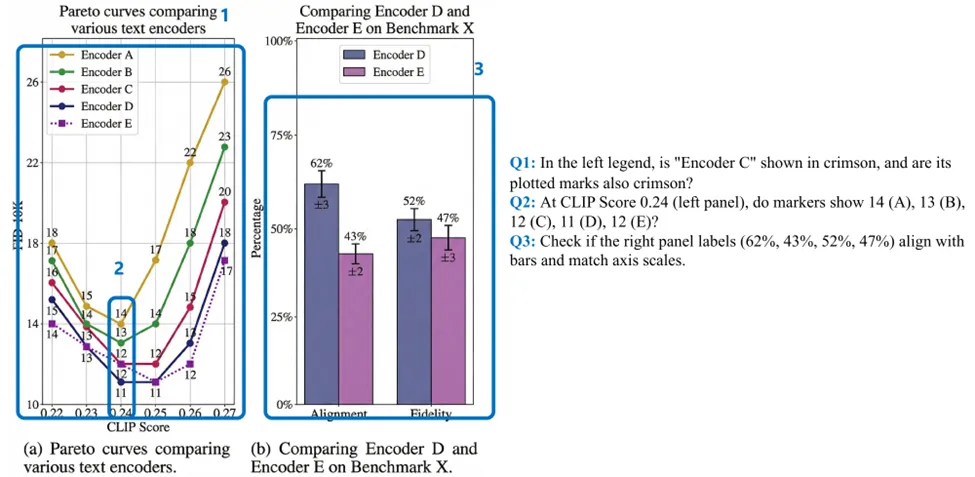

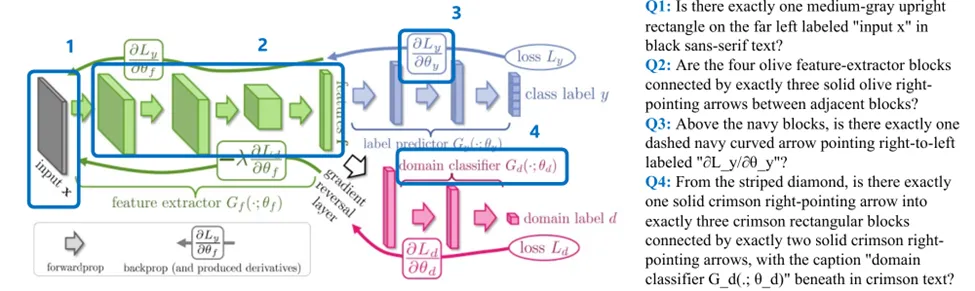
图2:BizGenEval五类商业题材示例图
拒绝“无效数据”:从高质量构造到精细化评估的全链路升级
在数据构造方面,BizGenEval 摒弃了依赖模型随机生成的方式,全程采用“人工精筛 + 专业打磨”的高标准方案,精心打造了400个具有代表性的专业评测样例,以确保评估结果真正贴近实际应用需求:
- 300 条真实内容需求:围绕文本、布局和属性等核心评估要素,研究员们从专业的在线来源中人工筛选、收集了真实的商业设计范例。基于这些真实的参考资料,再结合大语言模型与人类专家的协同改写,进而生成特定于任务的提示词,高度还原了人类设计师在真实工作流中的确切需求。
- 100 条“硬核”知识推理任务:为进一步提升评测深度,BizGenEval额外引入了 100 个基于知识的提示词,涵盖物理、化学、数学、历史和艺术五个专业领域 。通过设计如“生成包含化学方程式、化学实验的教学幻灯片”等高难度推理任务,重点考察模型的知识理解与逻辑推理能力。
与此同时,在评估机制上,BizGenEval 也对传统方法进行了系统性重构。针对商业视觉文档中结构复杂、约束密集的特点,传统的全局相似度指标已难以胜任。为此,研究员们提出了结构化检查清单式(Checklist)评估体系,让细微瑕疵无所遁形:
- 针对每一条测试样例,由人类专家设计 20 项细粒度二元校验问题(是 / 否),逐项核验生成结果;
- 整套基准共包含 8000 个精细校验项,用于精准评估生成的图像是否满足复杂的视觉约束;
- 在评估环节,采用最先进的多模态大语言模型作为自动评判工具,以确保评估的准确性与可扩展性。
核心发现:能力分层已出现,但离真实生产仍有关键鸿沟
基于 BizGenEval 对 26 个主流图像生成模型的系统评测,可以看到一个非常清晰的趋势:当前商业视觉内容生成能力已经出现明显分层,头部商业 API 显著领先。以 Nano-Banana-Pro 和 Nano-Banana-2.0 为代表的模型,在五大题材上的平均成绩分别达到 76.7/93.7 和 68.5/92.5;相比之下,大量模型在更严格的测试集(hard-set)上得分较低,说明它们虽然可以生成“看起来不错”的结果,但距离真实商业场景所要求的稳定可用性还有明显差距。
更进一步看,幻灯片、网页和海报相对更容易,而图表与科学插图明显更具挑战性。即便是 GPT-Image-1.5 这样的强模型,在这两个题材上的 hard-set 分数也下降到 28.2 和 27.8,反映出精确数值渲染、结构关系表达和复杂约束满足,依然是行业共性难题。
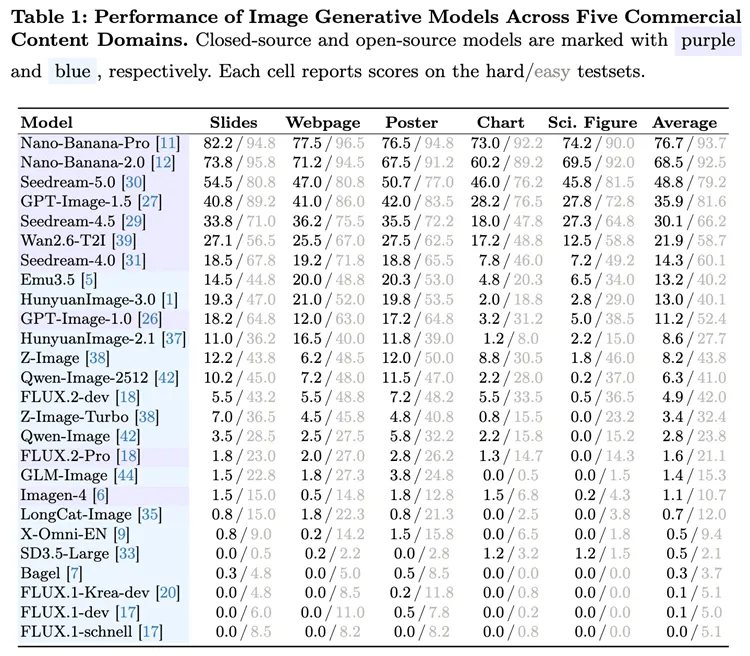
表1:前沿图像生成模型在五类商业视觉内容场景中的性能对比
从能力维度上看,当前模型的真正短板不只是“美观度”,而是“可控性”和“可验证性”。头部模型在“文本渲染”和“基于知识的推理”上已经表现出较强能力,例如 Nano-Banana-Pro 在这两个维度上分别达到 86.4/95.0 和 82.6/96.2;但在“布局控制”和“属性绑定”等精细控制任务上,表现仍明显受限。这意味着,复杂版式控制、空间关系建模和细粒度属性绑定依然没有被真正解决。这进一步说明,商业视觉内容生成的核心挑战,并非“生成一张像样的图”,而是“将正确的信息,以正确的形式,放在正确的位置上”。
与此同时,研究还发现,自然图像基准(benchmark)上的高分并不能直接迁移到商业场景,例如 GPT-Image-1.0 和 Qwen-Image 在 GenEval 上表现优异,但在 BizGenEval 上却排名靠后,证明了商业内容生成需要一套不同于自然图像生成的系统能力。
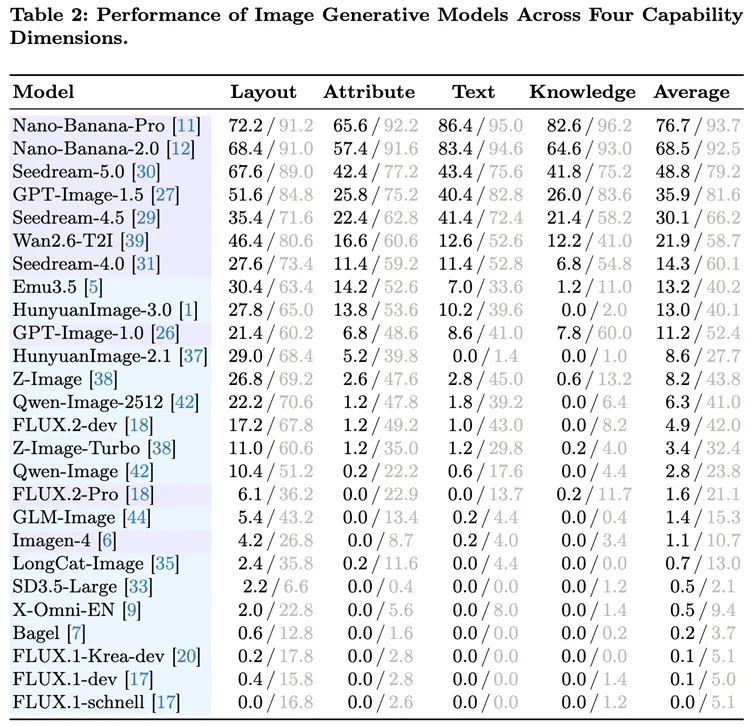
表2:前沿图像生成模型在四项核心能力维度上的性能对比
明晰能力差距,方能更好地前行
BizGenEval 的意义不仅在于补齐了一项关键评测基准,更在首次系统性地回答了一个面向真实落地的问题:当生成式 AI 从“生成图像”走向“生成可直接使用的商业内容”时,能力短板究竟在哪里?
实验结果表明,当前模型已初步具备商业视觉内容的风格生成能力,但在精确文本生成、严格布局控制、属性指定和知识一致性等决定实际可用性的核心能力上,仍存在显著不足。也正因此,BizGenEval 希望提供的不仅是一份“成绩单”,更是一把真正面向产业场景的“标尺”,帮助科研人员和产业界看清差距,并为下一代商业视觉内容生成模型指出更具体的优化方向。

图3:不同前沿模型在五大商业题材的性能差异