编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。
4月23日至4月27日,深度学习与表征学习领域最负盛名的学术会议之一的ICLR,将在巴西里约热内卢举行。我们将通过两期“科研上新”为大家带来多篇微软亚洲研究院入选 ICLR 2026的精选论文解读。第一期的研究工作涵盖强化学习基础理论分析、长上下文推理和代码生成验证的专项优化、智能体探索能力的优化等。
本期内容速览
1.理论视角分析,语言模型规划中强化学习的收益与陷阱
2.基于智能体奖励反馈的代码美学优化
3.EMPO²:基于记忆增强与混合优化的高搜索效率智能体
4.EvoTest:面向自我完善智能体系统的进化测试时学习
5.LoongRL:面向长上下文高级推理的强化学习(Oral)
6.ProRe:通过推理器-执行器协作实现的GUI智能体主动奖励系统
7.ReVeal:通过可靠自我验证实现的自演化代码智能体
1.理论视角分析,语言模型规划中强化学习的收益与陷阱

论文链接:https://openreview.net/forum?id=34a6DfHOUF (opens in new tab)
尽管强化学习已被广泛用于增强大语言模型的规划能力,但其背后的理论机制尚不清晰。为此,微软亚洲研究院的研究员们构建了一个基于图的规划抽象框架,从理论层面分析了策略梯度(PG)与Q-learning两类主流强化学习方法在LLMs规划任务中的优势与局限。
研究员们发现,监督微调容易使模型依赖训练数据中的共现关系产生“退化解”,而强化学习通过探索机制才能学到真正可泛化的规划策略。但策略梯度方法存在“多样性坍塌”问题,即在训练数据上达到最优准确率后,输出分布的多样性仍然持续下降。
相比之下,Q-learning不仅支持离策略学习(off-policy),还能在收敛时保持输出多样性。然而,若奖励函数设计不当,Q-learning会产生Q值偏差,反而损害模型性能。最后,在Blocksworld这一经典规划基准上的实验结果验证了上述理论分析在真实任务中的有效性。
2.基于智能体奖励反馈的代码美学优化

论文链接:https://openreview.net/forum?id=Q87kwGI6bx (opens in new tab)
尽管大语言模型在代码生成等任务上表现卓越,但其在生成图表、网页等视觉导向的代码时,往往只关注功能实现,忽视了布局、色彩和交互等美学维度,导致产出效果不佳。
为应对这一挑战,研究员们提出了一套完整的代码美学优化流程:首先构建了包含约35.8万高质量样本的大规模指令微调数据集AesCode-358K,涵盖Python可视化和网页设计;随后引入“智能体奖励反馈”机制,利用多智能体系统从代码可执行性、静态视觉美感和动态交互体验三个维度进行评估;在此基础上,研究进一步提出GRPO-AR算法,将多维度奖励信号融入强化学习,以联合优化代码的功能性与美学表现,并配套开发了用于系统性评估的OpenDesign基准。
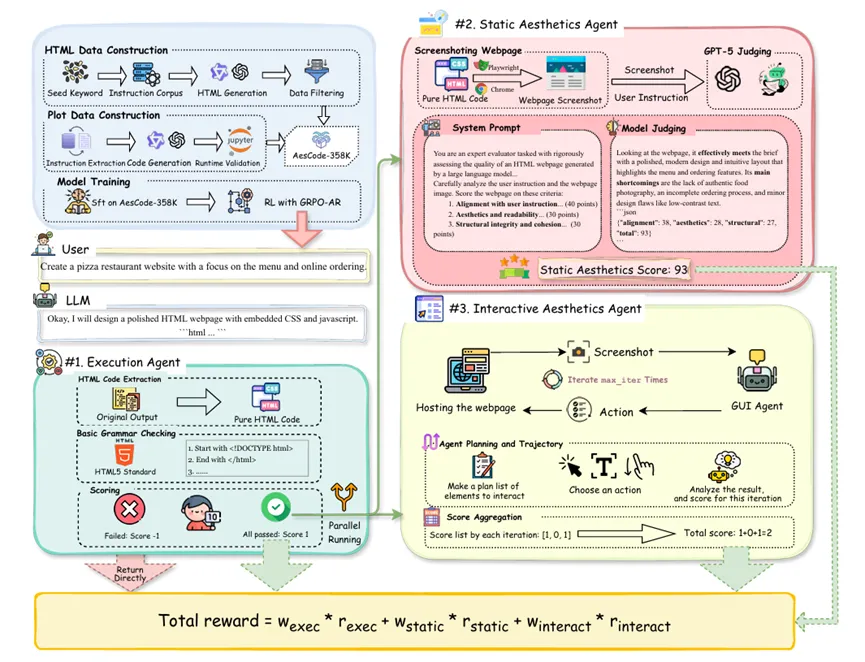
实验结果表明,先在AesCode-358K上进行监督微调,再结合智能体奖励反馈进行强化学习,能显著提升模型在OpenDesign及PandasPlotBench等基准上的表现。最终,仅40亿参数的AesCoder-4B模型在美学质量上超越了GPT-4o和GPT-4.1,其性能甚至可与参数量达480B–685B的超大规模开源模型相媲美,充分验证了该方案在提升代码美学方面的有效性。
3.EMPO2:基于记忆增强与混合优化的高搜索效率智能体

论文链接:https://openreview.net/forum?id=UOzxviKVFO (opens in new tab)
GitHub链接:https://github.com/microsoft/agent-lightning/tree/main/contrib/recipes/envs (opens in new tab)
在强化学习训练大语言模型智能体时,如何平衡“利用已知知识”与“探索未知状态”是一个关键挑战。现有方法过度依赖预训练知识,在需要主动探索新状态的复杂交互环境中往往表现不佳。
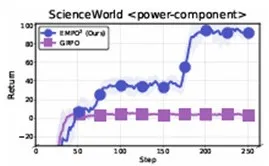
微软亚洲研究院的研究员们提出了EMPO²框架,它通过非参数记忆模块存储过往经验,并利用基于状态新颖性的内在奖励来激励探索。其核心是混合策略优化机制:在“带记忆”模式下进行采样,以发现更优策略;随后通过离策略更新,将带记忆的轨迹中的优质经验蒸馏到不带记忆的策略中,从而提升模型的固有探索能力。
实验表明,EMPO²在ScienceWorld和WebShop环境中,性能分别比基线方法GRPO提升了128.6%和11.3%。更重要的是,该智能体展现出强大的泛化能力,在分布外测试中仅需少量带记忆的试错即可快速适应新任务,且无需更新模型参数。
4.EvoTest:面向自我完善智能体系统的进化测试时学习

论文链接:https://openreview.net/forum?id=JFnnajbkvP (opens in new tab)
当前的大语言模型智能体在部署后,其能力往往被固化,面对未知或复杂环境时,难以在测试阶段即时学习新技能,这限制了其在实际动态场景中的应用。为系统性评估这一“测试时学习”能力,研究员们构建了 Jericho Test-Time Learning (J-TTL) 基准。该基准要求智能体在连续多轮游玩同一款文本冒险游戏的过程中,仅依靠自身经验进行策略改进,模拟了真实世界中智能体需要快速适应新任务的场景。
为解决此问题,研究员们提出了 EvoTest 框架,这是一种基于进化算法的测试时学习系统。它无需进行模型微调或梯度更新,而是通过一个“执行智能体”负责与环境交互,并由一个“进化智能体”分析每轮的交互记录,对下一轮的系统配置(包括策略提示、记忆库、超参数和工具使用流程)进行“进化”式修改。这种方法本质上是将智能体视为一个完整的、可通过自然语言描述的程序,利用进化算法在测试时对其进行优化。
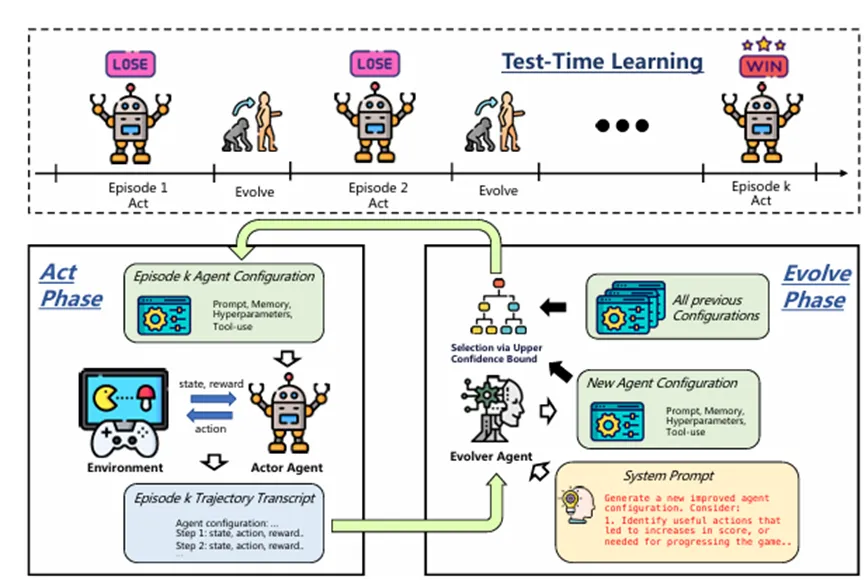
实验结果表明,在 J-TTL 基准上,现有方法(如反思、记忆增强或在线强化学习)均难以取得有效进展,而 EvoTest 能够持续提升性能。值得注意的是,EvoTest 是目前唯一一个能够成功通关其中两款游戏(Detective 和 Library)的方法,而其他基线方法均未能通关任何游戏,证明了该无梯度进化框架在赋予智能体自我改进能力方面的有效性。
5.LoongRL:面向长上下文高级推理的强化学习(Oral)

论文链接:https://openreview.net/forum?id=o29E01Q6bv (opens in new tab)
长上下文推理是大语言模型的重要挑战之一。现有模型在长文本场景下往往更擅长浅层检索,但对跨文档、多跳、需要规划与逐步定位的信息整合能力仍然不足。同时,高质量的长上下文复杂推理数据较为稀缺,而直接在 128K 等超长上下文上开展强化学习训练又会带来很高的计算开销。
对此,本篇ICLR 2026的Oral论文提出了一个面向长上下文复杂推理的强化学习框架LoongRL。其核心是KeyChain数据合成方法:从短文本多跳问答出发,通过在大量干扰文档中插入基于 UUID 的键值链,将真实问题隐藏在长上下文中,从而构造出需要“路径追踪-问题定位-信息检索-多步推理”才能完成的高难度任务。基于此,LoongRL 使用 GRPO 进行多阶段强化学习,并结合双向子串精确匹配的规则式验证奖励,在 16K 长度的混合训练数据上完成训练。
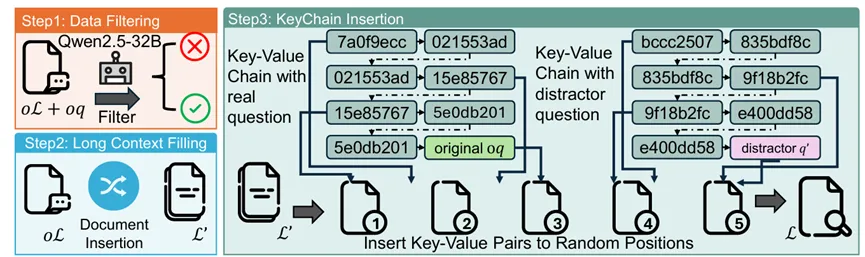
实验结果表明,LoongRL 学到了一种具有规划、检索、推理与复核特征的推理行为模式,并展现出较强的长度泛化能力:尽管训练仅在 16K 上进行,但模型在 128K 长上下文任务上仍能取得显著提升。在 Qwen2.5-7B 和 Qwen2.5-14B 上,其长上下文多跳问答准确率分别提升 23.5% 和 21.1%;其中 LoongRL-14B 在相关长上下文推理基准上达到 74.2,接近 o3-mini (74.5) 和 DeepSeek-R1 (74.9) 等更大模型。同时,该方法在长上下文检索测试(如 128K needle-in-a-haystack)上表现稳定,并基本保持了短上下文推理能力。
6.ProRe:通过推理器-执行器协作实现的GUI智能体主动奖励系统

论文链接:https://openreview.net/forum?id=xtysskccFc (opens in new tab)
在利用强化学习训练 GUI 智能体时,如何定义可靠的奖励信号是一个核心难题。由于难以获取应用程序的底层数据库或标准答案轨迹,传统的基于规则或静态“LLMs 即裁判”的奖励方法往往泛化能力不足、准确度有限,难以准确衡量智能体在复杂图形界面交互中的真实表现。
研究员们提出了主动式奖励系统ProRe。该方法构建了一个“推理器—执行器”协作架构:先由一个通用推理器(Reasoner)根据当前轨迹,动态规划出需要探查的关键界面状态;再由领域专用的评估执行器(Actor/Evaluator)主动与 GUI 环境交互,通过点击、输入等操作探针获取额外的观察和反馈;最后,推理器综合这些信息,为智能体的行为分配更准确、可验证的奖励。整个流程将奖励过程从被动打分转变为主动探测和验证。
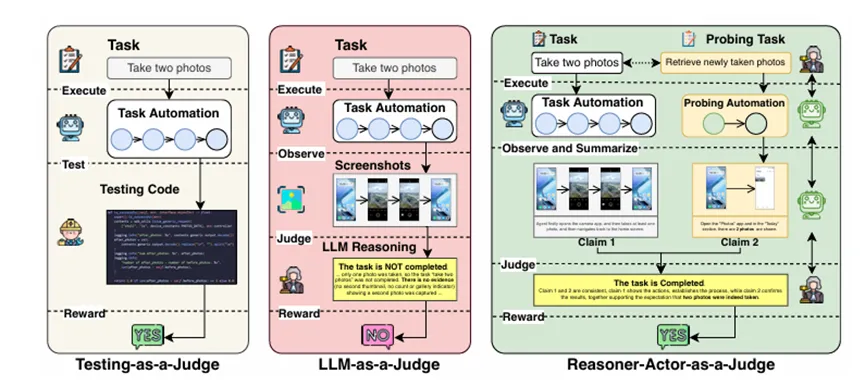
实验表明,ProRe 在超过 3000 条 GUI 交互轨迹上显著提升了奖励质量,其奖励准确率和 F1 分数相比基线方法最高提升了约 5.3% 和 19.4%。更重要的是,将 ProRe 作为外部奖励模块与先进的策略模型结合后,GUI 智能体的整体任务成功率最高提升了 22.4%,验证了该主动奖励机制在提升智能体性能方面的有效性。
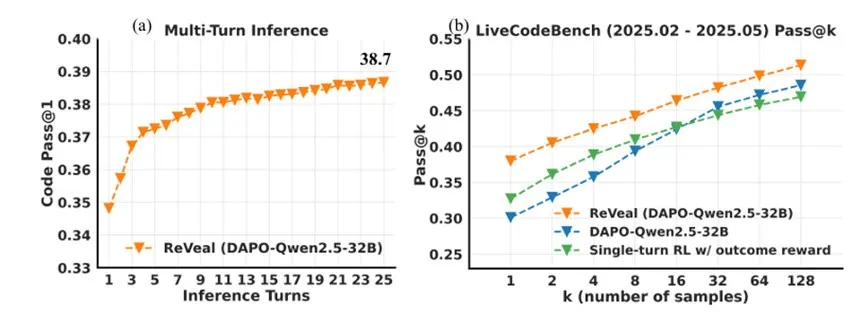
7.ReVeal:通过可靠自我验证实现的自演化代码智能体

论文链接:https://openreview.net/forum?id=q56ZI1Co43 (opens in new tab)
大语言模型在代码生成任务中,往往仅依赖结果奖励,缺乏可靠的自我验证能力,因此难以在真实环境中持续发现错误、修正代码并实现稳定的测试时扩展。为此,研究员们设计了一个多轮强化学习框架 ReVeal,核心思想是显式优化“自我验证”能力,并通过工具反馈驱动代码的持续进化。
ReVeal 将代码求解建模为“生成-验证”的交替迭代:模型首先生成初步代码,随后尝试编写测试用例并结合代码执行器等工具获取反馈,再根据反馈不断修改代码。该框架引入了 TAPO(Turn-Aware Policy Optimization)算法,结合结果奖励和逐轮稠密奖励,对每一轮的生成和验证行为进行细粒度的信用分配,从而协同提升模型的代码编写、测试设计与错误诊断能力。
实验表明,ReVeal 训练出的智能体具备强大的自我进化能力。在推理阶段,它能利用自我构建的测试和工具反馈,将代码持续优化二十轮以上,远超训练时的轮数限制。该方法在 LiveCodeBench 等基准上显著提升了 Pass@k 指标,展示了更强的探索能力,为实现更鲁棒、自主的 AI 编程助手提供了可扩展的新范式。