Enterprise AI has made building agents faster than ever. But teaching those agents how your organization works still means feeding knowledge in as documents and custom instructions or standing up a data science team to run the training, evaluation, and optimization cycles yourself. For IT leaders running agents at scale, that’s a ceiling on how much institutional knowledge your systems can hold, and an overhead that grows with every agent you add.
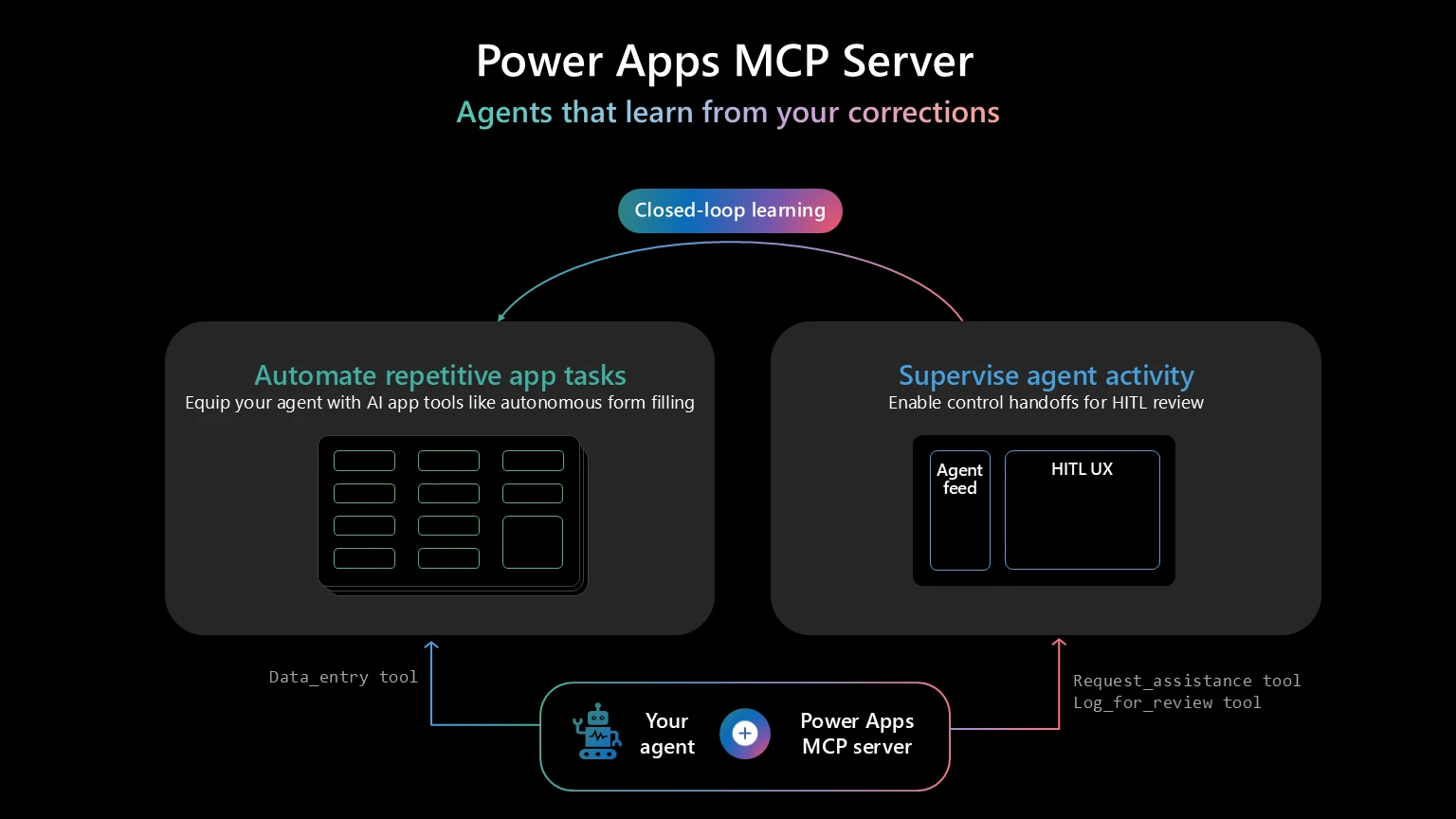
Today, we’re introducing closed-loop learning for agents connected to the Power Apps MCP server, starting with the data entry tool. Every correction a user makes through the Agent feed persists as structured memory. On future runs, the agent retrieves that memory and applies it. Over time, those corrections consolidate into organization-wide patterns the agent applies across tasks. The feedback loop runs automatically in production. Nothing to configure, no data pipelines to build.
How closed-loop learning works
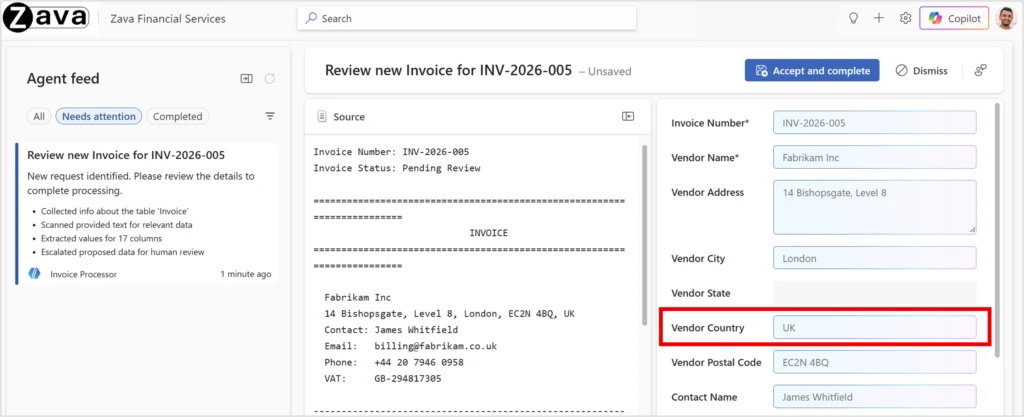
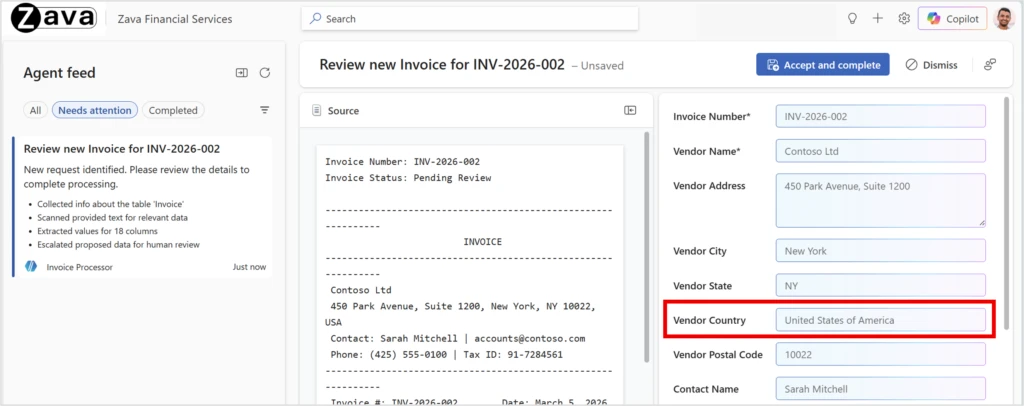
Say a finance team has an agent to process vendor invoices. The agent uses the data entry tool in the Power Apps MCP server to extract supplier names, addresses, and totals from PDFs. Most fields come through correctly, and the agent correctly fills in “UK” from the document, but the organization requires it to be normalized to “United Kingdom.” A user corrects it in the Agent feed. After a handful of corrections like this, the pattern becomes the agent’s memory. The next invoice with “UK” gets “United Kingdom” automatically. Over time, the system learns the pattern: abbreviations like “USA” or “DE” get expanded too. The agent also learns by example: it retrieves similar memories to the current request and applies the same processing steps used previously.
Think of it like a driving instructor in the passenger seat. A student merges without checking the blind spot; the instructor corrects them, and the student remembers it for next time, because they wrote it down. That’s the first layer: memory-based optimization, the mechanism that captures individual corrections and applies them on future runs.
Corrections get you through the driving test. Patterns make you a confident driver. That’s the second layer: Genetic-Pareto optimization, an evolutionary prompt optimization technique. Memory-based optimization generalizes from the corrections it remembers. Genetic-Pareto goes further, distilling those corrections into rules compiled into the agent’s instructions, so the principle becomes the agent’s default behavior rather than a pattern it must retrieve each time. Both layers are live today for the data entry tool.
Both mechanisms run with the rigor of a production machine learning pipeline. Unlike the memory features built into most AI assistants, which personalize the experience for an individual user, closed-loop learning improves task accuracy for everyone using your organization’s agent. The learning stays scoped to your business process and governed by your tenant.
Inside the research
The approach
Today’s techniques for adapting Large Language Models don’t close the feedback loop between deployment and improvement. Retrieval-augmented generation (RAG) surfaces documents at inference time but doesn’t learn from outcomes. Fine-tuning adapts the model but requires a training and deployment cycle for every update. Open-loop prompt optimization improves a fixed prompt offline but doesn’t incorporate live feedback.
Closed-loop learning closes the gap through two complementary mechanisms. Memory-based optimization captures user corrections as structured memories retrieved at inference time, giving the agent immediate recall. Genetic-Pareto optimization periodically distills those memories into generalized rules using evolutionary prompt optimization, so the agent applies what it’s learned to cases it hasn’t seen. The agent acts, a user corrects, the system learns, the next action improves.
Closed-loop learning builds on two open-source projects. Memory-based optimization takes inspiration from Memento, though our implementation has evolved significantly to fit the Power Apps MCP server’s architecture. Genetic-Pareto optimization is implemented via GEPA, integrated through DSPy, Stanford’s framework for programmatic LLM optimization.
The evaluation
The benchmark had to reflect enterprise data entry in practice. One of our early customers, the UK Electoral Commission, processes thousands of invoices annually from suppliers based in the UK, US, Ireland, and other countries. Each invoice demands structured extraction of supplier name, address, country, and total expenditure, with conventions that vary by supplier country and source document. The corrections the agent must learn are the organization-specific conventions that turn a correct extraction into a usable one.
We evaluated four configurations on a dataset of 100 invoices across 10 independent runs, reporting the average score across runs with 95% confidence intervals. The primary metric is F1 score, balancing precision (are the predictions correct?) with recall (is the model predicting all the expected fields?). Our quality bar is strict: did the user save exactly what the agent predicted, with zero edits? By that measure, a prediction of “UK” when the organization’s records use “United Kingdom” is a quality gap, because the user still had to correct it.
The results
These results are from pre-rollout offline simulation on UK Electoral Commission dataset. The data entry tool extracts content from invoices reliably. The gap is between that raw extraction and the format and conventions the organization expects. Closed-loop learning bridges that gap, calibrating the agent to the business. Across 4277 field instances, closed-loop learning decreased the share of fields users had to edit from 64% to 48%: 1045 fewer fields requiring manual correction.
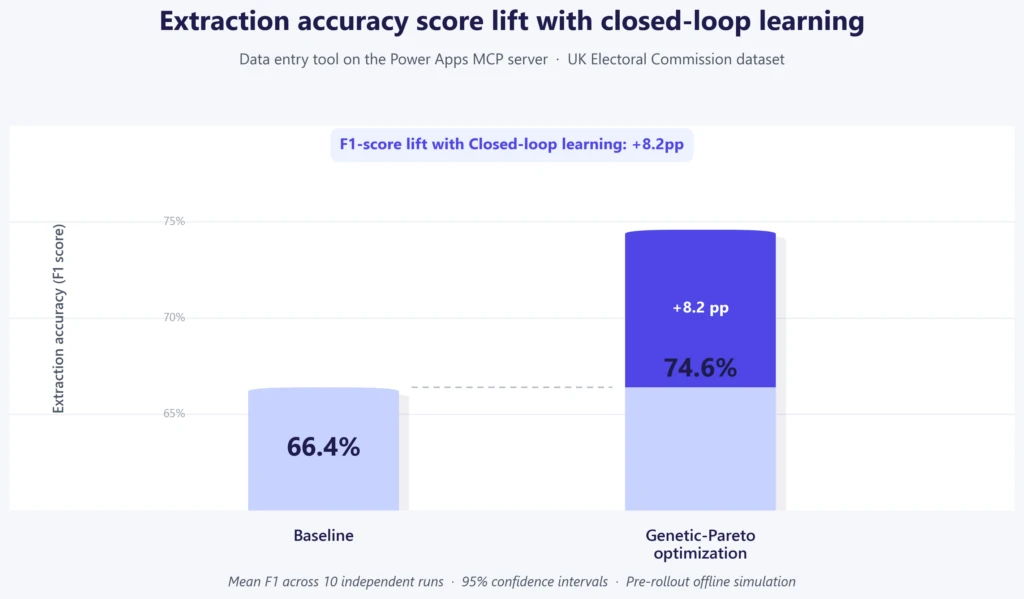
In 10 independent runs, Genetic-Pareto improved F1 score over the baseline from 66.4% to 74.6%, an 8.2 percentage point improvement.
The optimized prompt outperformed the baseline in all 10 runs, with non-overlapping confidence intervals and a positive confidence interval for the difference.
How Genetic-Pareto calibrated the agent
The F1 number tells part of the story. The baseline typically extracts the right information from the invoice; the gap is in how the business needs that information presented. A supplier name shown as a brand tag rather than the legal entity. An address combined into one line rather than splitting across the fields the organization expects. A total reflecting the ex-VAT amount rather than the gross invoice total.
In one sample run, Genetic-Pareto addressed 76 of 583 gaps in the baseline (a 13% reduction):
| Field category | Gaps addressed | What Genetic-Pareto learned |
| Addresses | 59 | UK formatting heuristics: town + postcode splitting, Scottish or island locality handling, supplier-only address extraction |
| Total Expenditure | 12 | Use gross invoice total (including VAT), sum multiple invoices from same supplier, ignore partial amounts |
| Supplier Names | 5 | Use legal entity name from invoice header, not brand tags, remittance agents, or “Bill To” sections |
These are taste and preference gaps. Genetic-Pareto closes them by calibrating the agent to how the organization structures its data. The gains were most pronounced when specific corrections mapped to a generalized principle. Country accuracy alone jumped from 11% to 78% after Genetic-Pareto learned to expand abbreviated country names. A broader evaluation of additional customers is in progress to validate and expand these findings.
Closing the loop
This evaluation and rollout loop a data science team typically runs happens automatically inside your tenant, through the Power Apps MCP server. The system generates a candidate prompt, runs a shadow experiment (each request uses the current prompt for the user-facing result while the same input is scored in parallel on the candidate), and uses statistical validation (hypothesis testing and power analysis) to decide whether the candidate is measurably better. When it clears the threshold, the candidate automatically becomes the new baseline, and every subsequent request runs on the improved version.
What comes next
Closed-loop learning will extend across more agentic workflows on the Power Apps MCP server over the coming weeks.
The gap between passing the driving test and feeling confident behind the wheel is experience. Closed-loop learning gives agents that experience.
Get started: Add the data entry tool to your agent on the Power Apps MCP server and give your agent a memory.